CapsFusion
- 世界知识和文本复杂度对文生图的影响
1 Introduction
1.1 Problem Statement
web上存在的大规模多模态数据,尤其是以文图对为代表的数据噪音非常多而且不够好。 在最近的工作中,用模型生成的prompt提高了模型生成图片的能力。 但是生成的描述词在扩展问题和世界知识两个方面产生了负面影响。 经过进一步实验,过分简化的语言结构导致了细节丧失,这是生成式的描述词的问题。 因此提出了capsfusion来解决这个问题。
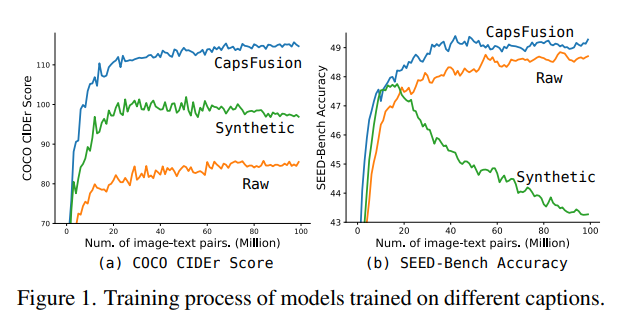
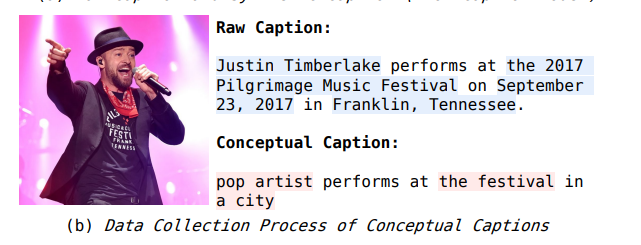
生成式图片描述模型BLIP等会产生这样问题的原因是:COCO和conceptual captions这样的学术数据集将专有名词替换成了类名,正如上图中红色和蓝色标注出的部分一样。 这样过分的简化隐去了世界知识,降低了学习的难度,从而导致了扩展性能和世界知识的学习都成为LMM的阻碍。
这个问题可以转化成现有的生成描述的模型不够好,我们既要去掉噪音还要保持先验知识。 从而期望我们的模型在这个数据集上训练能够得到scalable和knowlegable 两个特性。
1.2 Stated Contribution
- 提示词质量远远超过了之前的方法
- 训练出来的模型有更好的指标。
- 展示了强大的可扩展性和包含丰富的世界知识
2 Related Work
2.1 Image-text enhancement
LaCLIP(Improving clip training with language rewrites.)用LLM改写数据,但是由于严重的幻觉导致模型性能受限。
这两篇工作【Improving multimodal datasets with image captioning】【In search of the next generation of multimodal datasets.】调研了混合生成和原始数据来改进CLIP的方法。
同期工作VeCLIP用LLM直接推理,但是Capfusion做了推断。
2.1 Large MultiModal Models
现在多模态大模型的主要训练方法是next-token prediction. 另一类同时预测image和text token.
3 Method
这个图足够清楚 不需要解说了 重点来看下实验
4 Experiment
4.1 Dataset Construction
文图对和文视频对都会讨论配对数量和文本长度两个问题。 文本的多样性对模型的大小非常重要。 文本本身是非常强的监督信号。
CAPSFUS-120M 包含7.13 ×107 22.74
4.2 Model Evaluation
当然这个工作要做数据集开销还行,但是要做对比实验就很夸张了:
The 100M scale training costs 40 hours with 16 A800-80G GPUs.
5 Summary
这个motivation非常好,其实更更重要的是如何定位这个问题;
方法非常清晰合理,至于微调Llama还是不微调Llama,不是这个工作的核心。
5.1 Relative Position
非常重要的topic : data generation for model scalibility (and world knowledge)
5.2 LaCLIP summary
Motivation(动机)
- 输入不对称性:在CLIP的训练过程中,图像输入进行了数据增强,而文本输入则保持不变,这导致输入数据的不对称性。
- 监督信号限制:图像编码器从语言方面接受的监督信号较少,因为同一图像总是与相同的文本配对。
- 过拟合风险:文本编码器在每一轮训练中都会遇到相同的文本,这增加了过拟合的风险,并可能影响模型的zero-shot迁移能力。
Contribution(贡献)
- 文本增强方法:LaCLIP提出了一种新的文本增强方法,利用大型语言模型(如LLaMA)的ICL(In-Context Learning)能力,通过重写文本来增加数据的多样性。
- 保持原始概念:重写的文本在句子结构和词汇上具有多样性,同时保留了原始文本的关键概念和意义。
- 无需额外计算或内存开销:在训练过程中,LaCLIP通过随机选择原始文本或重写的版本作为文本增强,显著提高了CLIP的迁移性能,而不增加训练期间的计算或内存开销。
- 性能提升:在多个数据集(如CC3M、CC12M、RedCaps和LAION-400M)上的广泛实验表明,使用语言重写的CLIP预训练显著提高了迁移性能。例如,在ImageNet的zero-shot准确率上,LaCLIP在CC12M上比CLIP提高了8.2%,在LAION-400M上提高了2.4%。
6 Comments
这个image-text data enhancement的工作可以给我们改写prompt的时候提供一些借鉴。
其中提到的幻觉-可扩展性-世界知识的问题也值得我们去注意。