Classifier-free Diffusion Guidance
saturated colors :色彩绚丽
variance-preserving Markov process:保方差马尔可夫过程
1 Introduction
Motivation: 训练Classifier会让Difffusion训练更加复杂,希望没有Classifier也可以做Guidance的方法。 混合一个conditional diffusion 的score和一个unconditional diffusion。
原文:classifier-free guidance instead mixes the score estimates of a conditional diffusion model and a jointly trained unconditional diffusion model
但这两个模型可以用同一个模型表示,无条件生成的时候将y设置为空即可,公式可以表示为:
训练时只需要以一定概率将条件置空即可,代码表示为:
# core function of Dataset Class
def __getitem__(self, ind):
if self.text_files is None or random() < self.uncond_p:
tokens, mask = get_uncond_tokens_mask(self.tokenizer)
else:
tokens, mask = self.get_caption(ind)
推理时,最终结果可以由条件生成和无条件生成的线性外推获得,生成效果可以引导系数可以调节,控制生成样本的逼真性和多样性的平衡。
2 Method
The amount of truncation in representation of BigGAN -> trade off between FID and IS.
2.0 How does Classifier Guidance Work?
关于 Classifier Guidance的博客
Classifier Guidance的核心是:将无条件概率生成模型转换为有条件概率生成模型。
首先由贝叶斯公式:
对两边求对数:
对两边求关于
又有:
所以:
从这个公式中,我们发现,模型在条件y下生成的图片被分解成 一个无条件生成的图片减去一个分类器的结果。 这个分类器被定义为:
2.0.1 Classifier Model 和 unconditional diffusion的关系
总结一下上面的推导过程:推导的目的在于通过贝叶斯公式将 条件生成器 和 分类器建立联系。 条件生成即
所以Classifier Model 和 uncondition diffusion的组合可以表示condition diffusion
现在我们的问题是:我们并不能总得到一个足够好的classifier model.
2.1 Classifier Free Guidance
从Classifer Guidance到Classifer-free Guidance我们都关注同一个问题:
将一个有条件的生成过程转换为一个无条件生成+一个有条件的生成。
要做到这一点,我们构造性地有:
对比Classifier Guidance公式:
其实发现分类器对应的是无条件的是条件生成的部分。 Guidance从一个Classifer变成了一个Diffusion。 这样我们省略了一个模型的复杂度。 现在问题变成了: 为什么这样做会有效呢? ->Anwser
3 Experiments
所有的实验围绕着FID和IS之间的平衡取舍展开。
3.1 Study On Guidance Strength
引导强度
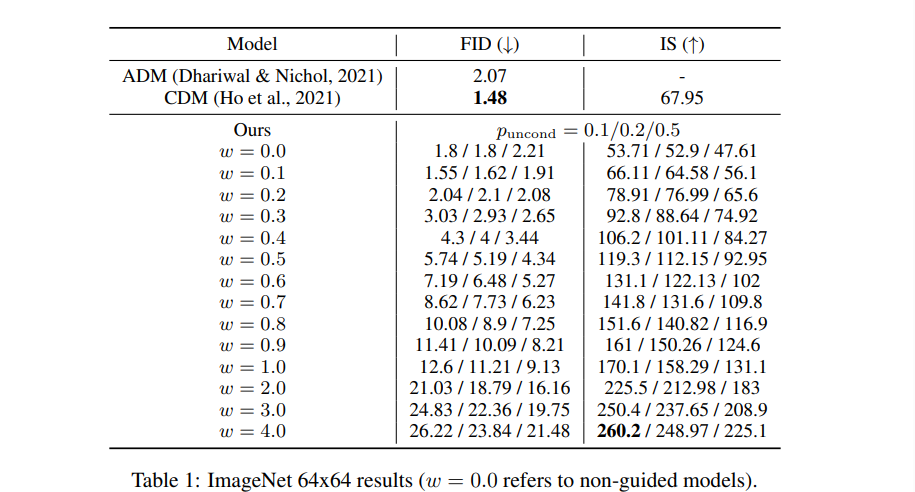
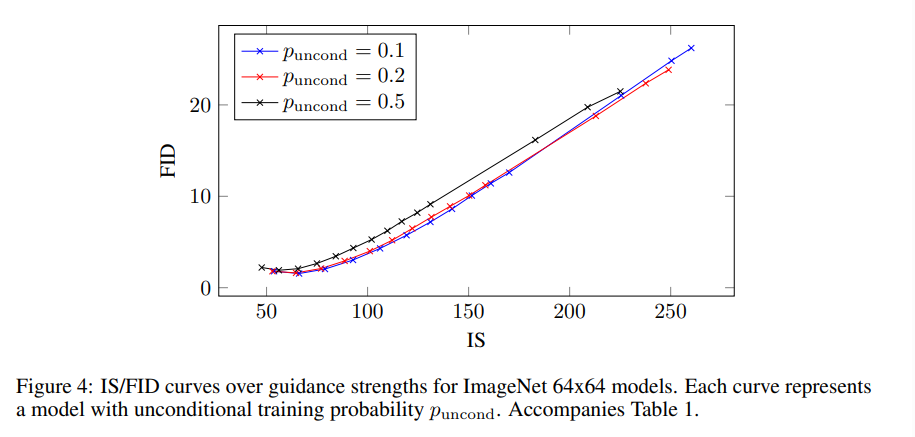
3.2 Varying Unconditional Probability
条件为none的比例对训练效果的影响: 在50%的时候训练效果最差。 结论是 只有合适的小比例的无条件生成会提高生成质量。
另一个有趣的点:在classifier guidance里面 小容量的小分类器会更加有用,和这里的小比例无条件生成是异曲同工之处。
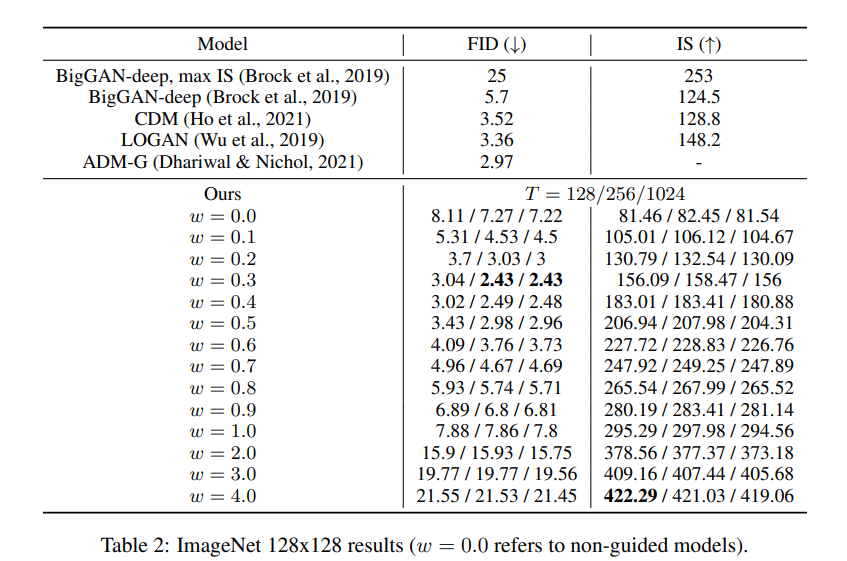
3.1 Varying Sample steps
采样步数对图片生成效果有着重要的作用,结果显式基本上T越大效果越好,但是在T=256时取得最好效果。
4 Discussion
原文:The most practical advantage of our classifier-free guidance method is its extreme simplicity: it is only a one-line change of code during training—to randomly drop out the conditioning—and during sampling—to mix the conditional and unconditional score estimates.
这一行代码已经在前面展示过了。
直观解释: 本文方法降低了无条件生成的可能性,升高了条件生成的可能性。
考虑到本文方法用的是Unconditional Diffusion替代Pretrained Classifier,采样速度可能会更慢。
从FID和IS效果分析可知,我们需要具体分析牺牲多样性带来的图片质量提升是否是可以接受的。
5 Comments
- 在MAE的分析里面也提到过的,这种Simple and Effective的改进是非常有价值的。
- 在本篇工作中,理论推导是远远复杂于代码改动的,个人认为理论解释有说服力。
- 理解Classifier Guidance对理解Classifier Free Guidance至关重要,所以本文讲Classifier Guidance反而跟多。 Classifier Free Guidance的方法反而犹如水到渠成一般自然。
- 本文似乎没有具体的训练资源消耗的描述,比较可惜。
Classifier Free Guidance通过构造损失函数的方式,将原来Classifier Guidance中的判别器替代为了一个无监督的Diffusion生成器。 通过在__getitem__方法里面按比例随机返回null condition。
6 Following Work
6.1 Imagen
Imagen流程如下:
- 首先,把prompt输入到frozen text encoder中,得到text embedding(这个表达已经蕴含了所有文本信息)
- text embedding输入到生成模型中,其实就是给模型信息,让他基于这个信息去生成图像。第一步先成低分辨率的图像,然后再串联2个super-resolution网络,这两个网络的输入是前面的低质量图像和text embedding。最终就可以输出高质量的图像。