DiffMorpher
DiffMorpher:图片到图片的变形
1 Introduction
1.1 Problem Statement
作者认为Diffusion的模型的Latent space相比于GAN的更加不规则,导致了平滑的插帧非常困难。
任务是从两张输入图片中生成一个插帧的Video,进行一个平滑的过渡。
1.2 Stated Contribution
所以作者为了解决这个问题,提出了用两个lora来捕捉两个图片的语音信息,然后再Lora参数之间进行插值,保证语义的一致性。
除此之外,作者加入了注意力插值和注入技术来自动调整图片之间的连续性。
2 Related Work
2.1 Classic Image Morphing
Image morphing是一个计算机视觉领域尚未解决的任务,有很多经典的图形学算法进行双向的图片展开来对图片进行平滑的插帧。 传统算法会有不能解决的一些不自然的现象。
最近大量数据的出现让数据驱动的方法越来越流行。
2.2 Image Editing via Diffusion Models
基于扩散模型的图形编辑方法: Imagen和Stable Diffusion等在大量图片文本对上预训练的文生图模型为图片编辑提供了先验。
目前有text-guided 和 drag-guided两种修改方法。 drag-guided就是把鼠标的点击动作编辑为隐向量。
2.3 Deep Interpolation
GAN模型的latent embedding space可以支持两个latent code的线性插值。 但是这个中间层的隐向量的质量不能被保证。
Diffusion Autoencoder尝试训练了更加合理的Latent Representation,但是对Stable Diffusion的兼容性受限。
3 Method
3.1 Diffusion Premilinaries
一个VAE+Unet组成的LDM
3.2 Lora Interpolation
关于Lora怎么工作的参考Lora,将新的参数更新到AB两个矩阵,合并为W+AB
让Lora拟合一张图片可以捕获这张图片的高级语义。 根据这个现象,用两个lora分别拟合
然后合并到Unet里面对噪音进行去噪。
3.3 Latent Interpolation
要生成
构造方法还是插值:
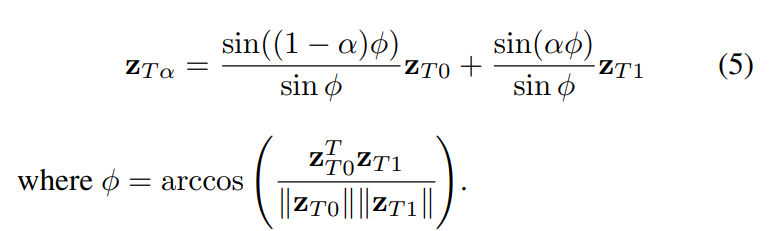
对隐向量进行球面线性插值,对条件向量进行线性插值
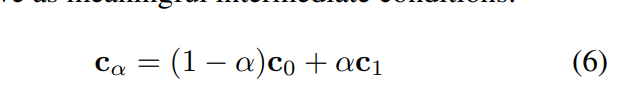
3.4 Attention Interploation
用插值的KV来替换Unet里面生成第a张图片的KV
3.5 AdaIn adjustment
用Adain对z0的每个通道都进行规范化
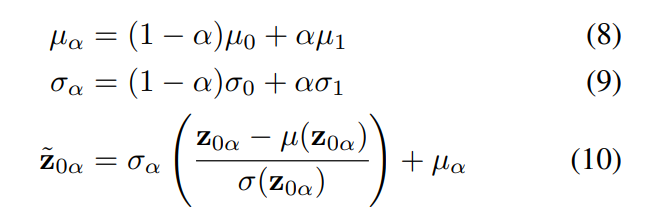
3.6 Resample alpha
以最小化两帧相邻图片之间perceptual角度为目标
4 Experiment
4.1 Implementation Details
没有用classifier free guidance
5 Summary
通过一个多层次的插值做到了image之间的插帧,可以生成video。
主要的创新点在插值两个lora的weight。
对lora的weight能够拟合单张图片的high level semantic feature的观察挺有意义。