Diffusion AutoEncoder
[CVPR22oral] Diffusion AutoEncoder
1 Introduction
1.1 Problem Statement
Diffusion模型的latent representation不能被其他任务高效利用
这篇文章关注的问题是:用diffusion做representation learning
1.2 Stated Contribution
他们方法可以把任何一张图片编码成一个由线性的语义向量和stohastic details code组成的特征。 可以应用在attribute-manipulation(属性编辑)等任务上。
这个两级的编码同时也可以提高去噪效率
并且在几个下游任务上表现良好
截止本文发布,github star 786
都用AE做representation learning了, 肯定有diffusion VAE了。 一搜还真有arxiv:2201.00308,引用了本篇
2 Related Work
3 Method
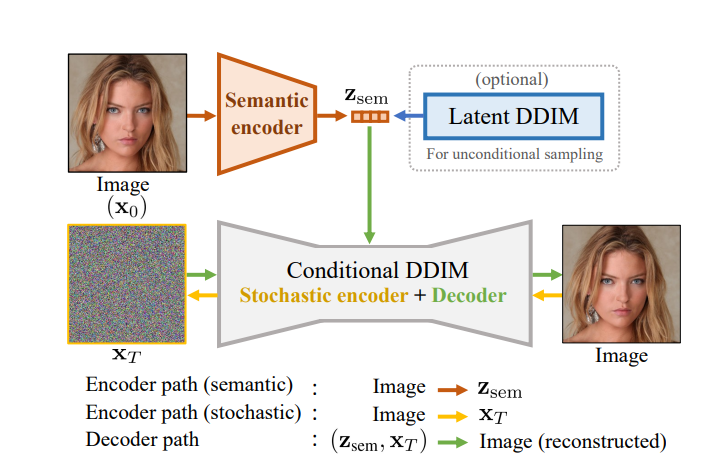
这个工作做了一个conditional DDIM, z_sem是一个512维度的向量,和StyleGAN的特征维度一样。 然后把这个作为条件加入到DDIM里面。 这里作者反复提到了低维特征和高维特征,认为z_sem负责提供高维语义信息,而噪音提供随机的细节信息。
再加上主图里面用的是人脸图片,这个暗示应该很明显了, 大概率先用的是stylegan的预训练模型做的验证。
3.1 conditional DDIM
上图中有个conditional DDIM,看似对DDIM做了改变,实际上从公式可知,需要改变的只是Unet.
在去噪音的过程中, z_sem可以看作是一个额外的条件,第T步去噪就被改写成了
在去噪网络中,输入也从
其他部分不变,用常见的
3.2 Semantic Encoder
Encoder 没有结构要求,论文用的Unet的实现
3.3 Stochastic Encoder
Conditional DDIM可以用来将图片编辑成一个stohastic subcode.
这个公式还挺有意思的,用一种条件加噪的方式,得到了一个x的隐向量
但是这样算
3.4 sampling with diffusion autoencoders
当我们给deocder加上一个条件的时候,这个diffusion就不是一个生成模型了,而是一个重建模型。
作者提到他们说VAE是一个好的选择,但是为了平衡信息的多项性和采样质量之间的关系,他们用了AE。
4 Experiment

重建的很好,然后也能改变细节
5 Summary
通过一个额外的encoder把generative model转变成了deocder. 这个工作在规范diffusion空间的隐向量上有一些启发。 但是个人感觉启发不多。
6 Comments
还不错的工作,还值得继续挖掘