Emu
1 Introduction
1.1 Problem Statement
1.2 Stated Contribution
在一个极高质量的小数据集上SFT可以提高模型的生成高质量图片的能力。
这个insight放到视频领域应该也是有用的,主流的预训练方法也都包括高质量小数据集FT。
作者将一个高质量的图片数据集训练的过程分为两个阶段:
- 第一个阶段是 knowledge learning
- 第二个阶段是 quality-tuning
实际上这个总结和latent diffusion对semantic compression和perceptual compression是一个观点。
作者还把quality tuning和instruction finetuning在LLM中的应用做了比较。
这里回到我们在scaling law时代需要面临的一个经典trade-off:
我们究竟是需要大量数据还是小量的高质量数据? 如果我们都需要的话,应该怎么样平衡他们之间的关系。 BERT- GPT系列证明了前者,也有工作反复证明后者也是work的。
这个工作先预训练了一个1.1B数据上的的模型,再用几千张高质量的数据集进行微调。 这个模型叫做LDM EMU, 超过了sdxl1.0.
作者也提出这个data-quality insight跟模型应该是无关的,在pixel diffusion, masked generative transformer上应该也是work的。
1.3 An interesting computation
- the resolution 1024x1024
- image pairs : 1.1 x 10 ^ 10
- ratio: 10490
2 Related Work
2.1 text-to-image models
2.2 fine-tuning T2I models
Personalization: 目前微调SD的主要目标之一
Adapter-based finetuning: ControlNet -adding conditional control ; Lora : efficient finetuning
InstructPix2Pix: instruction funetuning for diffusion models
2.3 Fine-tuning Language models
Llama2用了27k高质量数据微调好一个大语言模型。
3 Method
3.1 Arch
- AE-16 channel for better reconstruction performance
- 2.8B unet
- CLIP ViT-L + T5XXL for text embedding
3.2 HQ Alignment Data
- 自动筛选: OCR- CLIP etc
这个人类筛选数据的流程主要分为两个阶段,旨在筛选出高美感的图像。以下是流程的总结:
第一阶段:一般筛选
- 目标:优化召回率(recall),即尽可能排除通过自动过滤但质量中等或低的图像。
- 操作:训练一般标注员(generalist annotators)对图像池进行初步筛选,将图像数量减少到2万张。
第二阶段:专家筛选
- 目标:优化精确率(precision),即只选择最优秀的图像。
- 操作:聘请对摄影原则有深入理解的专家标注员(specialist annotators),进一步筛选图像,确保选出的图像具有最高的美学质量。
筛选标准
- 构图:图像应遵循专业摄影构图原则,如“三分法则”、“深度与层次”等。负面例子包括视觉重量不平衡、主体角度不佳或被遮挡、以及周围不重要的物体分散注意力。
- 光线:图像应具有动态光线和平衡的曝光,避免人工或乏味的光线,以及过暗或过曝的光线。
- 色彩和对比:图像应具有鲜艳的色彩和强烈的色彩对比,避免单色调或单一颜色主导整个画面的情况。
- 主体和背景:图像应有前景和背景元素之间的深度感,背景应简洁但不单调。主体应清晰可见,细节丰富。
- 附加主观评估:标注员需提供主观评估,回答几个问题以确保只保留极高美感的图像,例如:图像是否讲述了一个引人入胜的故事?是否可以显著改进?这是否是你见过的这类题材中最好的照片之一?
最终结果
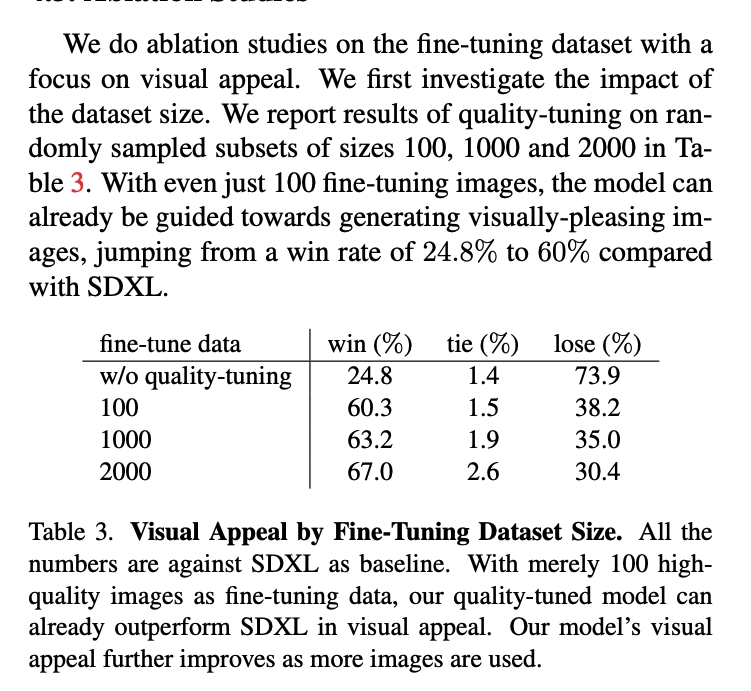
- 保留数量:通过该筛选流程,最终保留了2000张高质量图像。
- 后处理:为这些图像撰写了地面真实(ground-truth)描述。对于分辨率低于1024×1024的图像,使用一个diffusion进行上采样。
3.3 Quality Tuning
- bs 64
- nosie offset 0.1
- 15k iter : early stop
4 Experiment
4.1 Implementation Details
5 Summary
5.1 Relative Position
- PEFT
- data quality and data centric