Unconditional Diffusion
0 符号定义
记图片为x,在扩散模型中,通过给
前向加噪音过程:
后向去噪过程:
1 推导
1.1 前向过程
设
在等式的右边
重新整理一下参数:
那么
从而可以从
最后可以得到:
1.2 去噪过程
从
1.3 损失函数
计算Varicational Lower Bound
从而我们得到
接下来处理等式的右边:
因为:
得到:
第一个KL散度里面q不含可学习参数,可以忽略不计。
第二个KL散度地面,在“贝叶斯重写”的步骤中,加上了x_0的条件,使得KL散度里有两个
你们会推公式的人真的像在变魔法。
从1.2节#1.2 去噪过程可知
经过一些省略的操作最后将损失函数化简为
2 Training and Sampling

训练时: 随机采样加噪步数1-T,前向传播得到
注意网络预测到的是噪音
推断时:随机生成一个正态分布的图片,进行T步循环。 循环体内 预测出噪音后,用t步图片减去噪音,再除去方差得到t-1步图片。
- Algorithm 2中
是在去噪过程中逐步加入噪音,可以增加图片多样性,但是会让生成过程无法收敛。为了保证生成结果可以复现,也可以不加 - 在推断过程中,可以用simple_var策略,即把噪音方差假设为1,则去噪过程简化为
3 Comments
为什么余弦的加噪音过程要比线性的加噪音过程效果更好?
我认为直观的解释有两点:
- 参考cosine positional encoding,余弦噪音可以让模型学习一个潜在的和t相关的噪音预测能力
- 余弦噪音在每一步上噪音量不同,模型需要对输入的图片的噪音量有所感知,换句话说,避免模型short cut
4 DDPM implementation
To fill the gap between formulas and codes
注意:
4.1 前向过程
前向过程最终的目标是给定按照给定策略加噪音得到第t步图片的过程。
给定第t-1步的图片,可以得到第t步的图片:
前向过程的输入是图片
因此这个函数可以定义为:
def sample_forward(x_0,t,alpha_bars):
eps = torch.rand_like(x_0)
x_t = torch.sqrt(alpha_bars[t]) * x_0 + \
torch.sqrt(1-alpha_bars) * eps
return x_t
其中alpha_bars是由采样策略决定的数组,长度为t。
这个函数是一个torch style的伪代码,为了简洁所以没有用常见的类定义方法。
4.1.1 采样策略
采样策略即决定第t步噪音的方差和均值的超参数,不同的采样策略会影响加噪音的最大步数N。 举例两种最简单的采样策略:线性采样和余弦采样
超参数:
- min_beta : 2e-2
- max_beta : 1e-4
- time_step : 1000
- strategy: linear
线性采样
betas =torch.linspace(min_beta, max_beta,\
n_timestep, dtype=torch.float64)
余弦采样
timesteps = (torch.arange(n_timestep + 1, dtype=torch.float64) /
n_timestep + cosine_s)
alphas = timesteps / (1 + cosine_s) * np.pi / 2
alphas = torch.cos(alphas).pow(2)
alphas = alphas / alphas[0]
betas = 1 - alphas[1:] / alphas[:-1]
betas = np.clip(betas, a_min=0, a_max=0.999)
采样完成betas之后,还需要预先计算alpha_bars的值备用:
实现为:
alphas = 1- betas
alpha_bars = alphas.cumprod(dim=0)
#视情况可以给alpha_bars首位插入一个1,对齐下标用
4.2 后向过程
后向过程的目标是从噪音中进行N步去噪生成一张图片:
由加噪音过程:
得到去噪音过程:
在实验中,简化噪音方差为1可以减少计算量和提升效果
从而得到:
def sample_backward(self,x,t)
if t== 0:
noise = 0
if simple_var:
var = self.betas[t]
else:
var = self.betas[t] * self.alpha_bars[t] * (1-self.alpha_bars_prev[t])/(1-self.alpha_bars[t-1])
noise = torch.rand_like(x_t) * torch.sqrt(var)
eps = net(x_t,t)
mean = (x_t -(1 - self.alphas[t]) / torch.sqrt(1 - self.alpha_bars[t]) *eps) / torch.sqrt(self.alphas[t])
x_t_prev = mean + noise
return x_t_prev
5 DDIM implementation
DDIM是对DDPM采样进行加速的实现
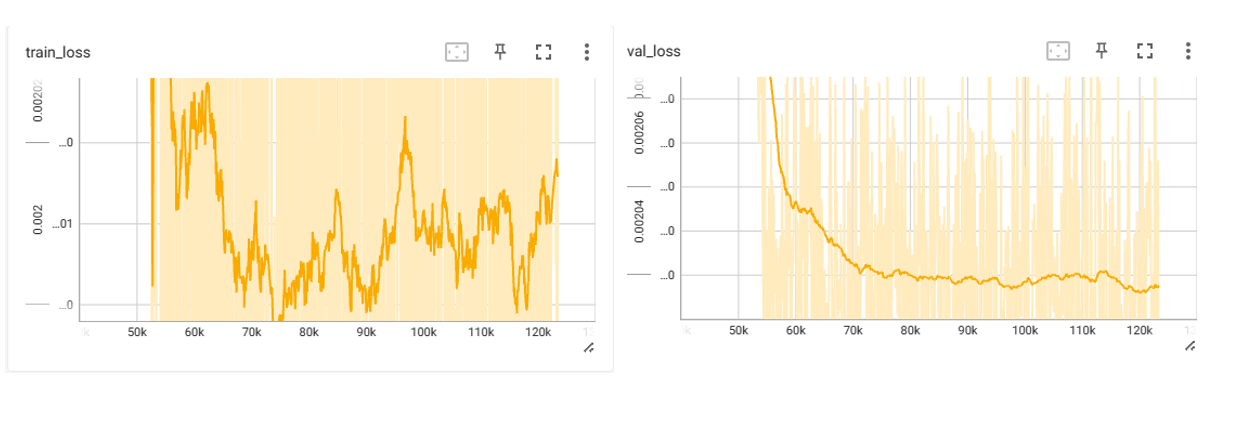
MNIST 实验结果
400个epoch batch_size=512
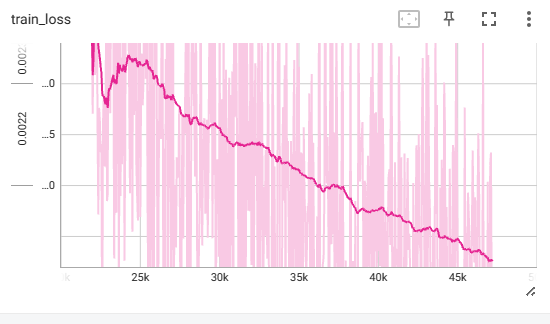
1200个epoch batch_size=512