AlignYourLatents
interleaved : 间隔
1 Introduction
Diffusion模型在GAN, 自回归Transformer等模型中在生成任务上表现最好。 Diffusion比Tranformer参数量少的同时提供了一种可以问题扩大规模保证稳定训练的选择。
2 Related Work
Diffusion Models and Latent Diffusion Models
3 Method
3.1 Turn Latent Image into Video Generators
这个小标题应该是受到排版问题所以没写全:
Turn Image Latents into Video Latents.
LDM可以被视为高质量的视频帧生成器,但是直接用来生成视频是不行的。 所以作者在现有的spatial layers插入temporal layer。
视频被按帧编码为
训练的时候每个批次的隐向量
在每一个被插入的时序层
损失函数记为
其中
3.1.1 Temporal Autoencoder Finetuning
Encoder是没有做出改变的。 Decoder在解码一个时间上连续的序列(temporally coherent sequence)的时候会有不自然的因素。 所以用一个3D卷积Discriminator对AE的Decoder进行带有时序信息的微调。
看起来是类似GAN
3.2 Long Video Generation
对一个T帧的视频加入T-S帧mask,让模型从S帧图片去预测剩下的T-S帧mask.
利用Classifier-free Diffusion Guidance的方法,按照一定比例空置text condition能够提高生成质量。
3.3 Temporal Interpolation
通过抹去中间帧的方式训练模型的插帧能力,提高FPS。
3.4 Temporal SR model
用超分辨率的方法提高视频的分辨率,但是naively增加一个SR模型会让视频的连贯性下降。 然后重复3.1里面的方法,插入时序层让超分模型能理解到视频信息。
4 Experiments
4.1 dataset
- 一个不公开的驾驶数据集
- WebVid-10M
4.2 Metrics
FVD 和 IS
评价指标参考Diffusion Preliminary
4.3 Architecture
LDM : High-resolution image synthesis with latent diffusion models
DM and Unet : Diffusion models beat GANs on image synthesis
Scheduler: DDIM
实验全是在私有数据上测的。
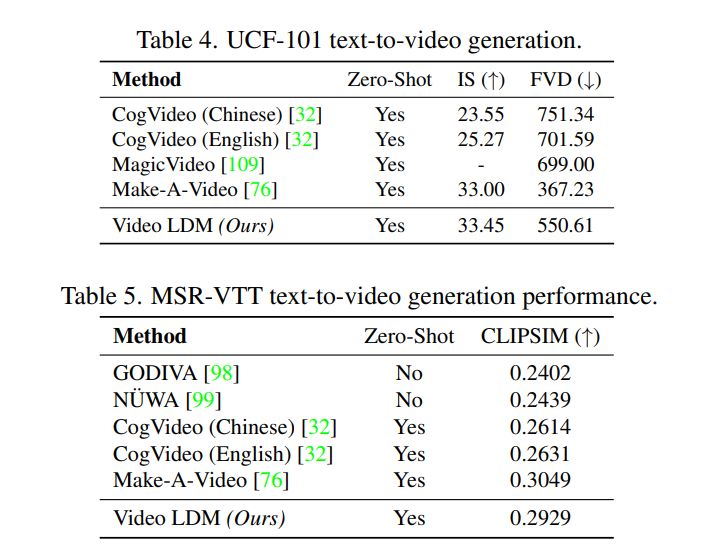
指标都比Make-A-Video差一点
4.4 利用SD的Latents
现在WebVid-10M上面微调SD的模型,效果还是不错的。
4.5 DreamBooth
用DreamBooth在图片生成上进行训练。

5 Comments
这个工作在Related Work中只提到了DM和LDM。 再加上Align Latents这个名字,说明作者对Latents非常关注,希望直接利用Latents from pretrained LDM。 作者压根没想从头训练一个VideoModel。
题外话.现在的diffusion相关的工作真的多啊。
5.1 Review
3.1.1节是不是太简单了 看完知道干了啥,不知道怎么干的
3.2 节的方法work但似乎没有novelty? 不知道之前的工作有没有这样做过。
这个方法或许可以在工程上实现,但是仅仅在一个LDM和一个SR里面插入temporal layer的方式有点____. 3.2和3.3利用mask机制进行更好效果生成。
SR是有用的。
利用DreamBooth做Personalize是非常趣的实验。
6 Implementation
开源情况: 有一个开源非官方实现但是没有训练好的Checkpoint