CogVideoX
1 Introduction
Diffusion-based Text2Video ViT foundation models.
2 Related Work
3 Method
4 Experiment
4.1 Implementation Details
5 Summary
5.1 Relative Position Encoding
6 Comments
7 Implementation
训练代码入口 train_video.py ,关键函数是forward_step 对应training_step , 里面进去之后,需要一个model.shared_step。
CogVideo这个代码怎么每一层都要Institiate_from_config一次。 这样看起来负担好重。
Nice Practice : Parallel Uniform Sampling
作者提出,在采样timestep的时候,各个device同时从[0,max_step]采样不如按照device进行线性划分,使得每个device采样的范围都不重复。 他的实现是这样的:
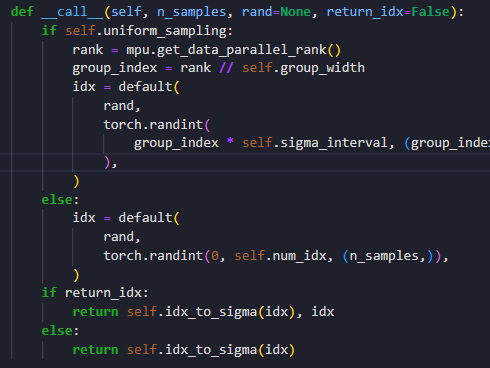
但是这个代码的问题是 tmd 怎么在很多类里面都有他手写并行代码的痕迹。如果要用PL实现的话,应该可以获得每个rank的值,然后randint一下就行。
7.1 SATVideoDiffusionEngine(nn.Module)
这里的model是SATVideoDiffusionEngine。 他包括了加噪去噪的过程,就是DDPM的逻辑。
7.1.1 VideoDiffusionLoss
他把加噪的过程写在这里了。 【?我直接一个黑人问号】
这里应该使用了一个min_snr的策略,有一个sigma_sampler负责采样这个sigma的值。 也就是噪音分布的方差。
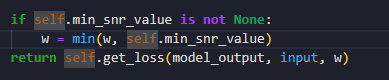
这个Loss_fn里面由于包含了加噪的过程。 所以这还涉及了加噪的代码。 sigma_sampling.py和discretizer.py。 这里的离散化不分主要是指sigma采样的方式。 sigma_sampling包装了一层uniform_sample 在多卡的时候可以用的。
这个sampling从EDM基类开始写。 就是一个exp(mean+std*z)的过程。
EDM对应的也有一个离散化过程。 就是一个线性的采样。
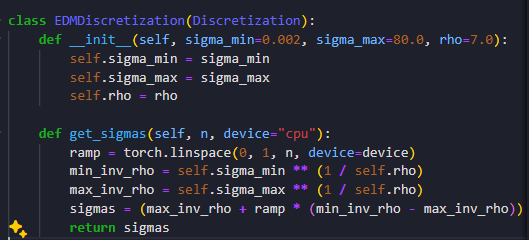
但是用的是他的一个子类ZeroSNRDDPMDiscretization ,当然还是重写这个get_sigmas,就是返回一下alphas_cumprod_sqrt就可以。 这个在DDPM里面都是默认的。
7.2 sat实现分析
SAT: SwissArmyTransformer 也是THUDM开发的系统。
这个库提供了一系列完整的训练框架和代码。 有一个自己的LoRA实现。 (你们THU能找到的代码能力过关的人真多)。
注册机制
正如其他框架,SAT也提供了一个注册机制。 既然现在没有事情干,那么我们就先分析一下这个注册机制。
typing是一个辅助python进行类型指定的模块。 这里常见的有Any表示任何不确定的类型,Optional提供可选的类型,List,Tuple,Dict,Unoin等指定类型的关键词。 这里有 点类似json语言。

这里register维护一个名字,和一些member,表示注册过的类的名字。 这里总的模型注册表是sta_models。 (图中最后一行)
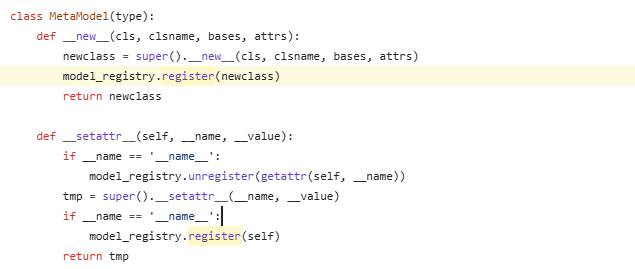
MetaModel继承了type类,用来辅助后面的模型类的定义,所以这里取名叫做元模型。 可以看到这里每一个继承了这个MetaModel的类都会注册为sat_models的一个新的member。 然后可以设置一些相关的值。
然后SAT定义了一个模型基类(BaseModel)。 继承torch.nn.Module,然后注册到sat_models这个member里面。 这个BaseModel是比较灵活的类,可以支持动态的模型结构。 首先他也有一个mixins,是一个moduleList,就是nn.Module组成的字典。 如果一个类是ModelMixin的子类,那么他就可以加入到这个mixins字典里面取。 这个mixins字典支持增删查。
然后就到了这个模型比较抽象的时候了。 他这里用了叫做collect_hooks的机制,来定义模型之间的关系,并且用来封装这个模型的forward过程。 具体做法是,BaseModel以一个Transformer模块(nn.Module)为基础,然后取检查mixins字典里面的情况,把他们加入hooks,然后在forward的时候更新hooks,根据这个hooks就可以进行forward。


所以这个lora_mixin直接加进去,不影响forward什么的。
8 CogVideo Merge 方案
- SATVideoDiffusion + train_video.forward_step*() : DDPM
- train_video.py -> video_io_utils
- from sat.training.deepspeed_training import training_main : pl.trainer
- sft.yaml + cogvideo-2b.yaml : configs/train/004-cogvideo-ft/config.yaml
- 类初始化方法和lvdm是一样的,omega config + get_obj_from_str + kwargs initialization
剩下的部分应该都是通过config实例化的,这样的话,他的结构(例如在loss class里面加噪音) 可以被隐藏。 以及sgm是一个比较完整的体系,尽量没必要去动他。
这个trainer的log机制和opensora的有点像,但是很丑
还有cogvideo这个命名方法有点离谱,叫sat是因为训练框架用了sat的框架,为了和diffusers的训练分开。 但是我们这里应该改成cogvideo-pl.trainer.
而且这个命名真的好想吐槽,他的discrete dnoiser实际上是noise schduler. 他的network才是denosier. 然后在loss里面加noise schdule的代码,这个可能是因为配合加噪策略的需要。
8.1 Lightning CogVideo Merge
8.1.2 Train
要训练的话,首先需要正确的初始化并性的一些配置。
8.1.3 Inference
DDIM_sampler包裹的model有一些要求,比如说要包含alpha属性,这些属于加噪音的过程。 但是cogvideo是放在scheduler里面的。
cogvideo包含sampler,并且这个sampler是一个可以定制的类。 这个sampler对外提供__call__函数,输入noise,condition etc.返回 latent space上的sample结果。 接下来通过一个decode函数把latents解码成视频。
所以这里cogvideo这个设计好的地方在于:
- sampler和denoiser解耦比较好,对Denoiser相关的框架开放的接口实际上只有一个__call__. 但是DDIM_sampler和DDPM两个类overlap更高。 DDIM_sampler在初始化的时候会直接拿model的参数。 就在DDIM.make_schedule函数里有一堆register buffer是依赖DDPM model给出的。
- 这个sampler灵活性更好,实际上并不假定任何采样器。 但是在inference.py里面默认的是DDIM_sampler。
如果我们对其到inference.py,那么可以对其到batch_sample_t2v,这样可以重用cogvideo的smaple。sample_batch_t2v返回的是视频。
这样我们需要做三件事情:
对齐sampler,对齐model.decode,对齐input