ControlVideo
Training-free Controllable Text-to-Video Generation
structural flickers: 结构性闪烁
1 Introduction
研究现状
- 现在的text2video模型训练起来太复杂,成本太高
- Controlnet 和 DDIM inversion 提供了给SD加入控制的方法
已有视频生成模型的问题:
- 帧间不连续性
- 在大幅度的视频里的不真实的动作
- 帧间变换的时候的结构性闪烁
在ControlNet的基础上加入了
- 帧间交互机制
- 插帧平滑器
- 层次采样来分别生成短视频
2 Related Work
2.1 Latent Diffusion Model
Latent Diffusion Model利用一个VAE将图片压缩到一个隐空间再重建回图片。Diffusion的前向传播和去噪过程都在隐空间上完成。
2.2 ControlNet
通过zero-convlution层给SD增加一个条件控制
3 Method
ControlVideo的目标是在一个motion序列c和文字条件
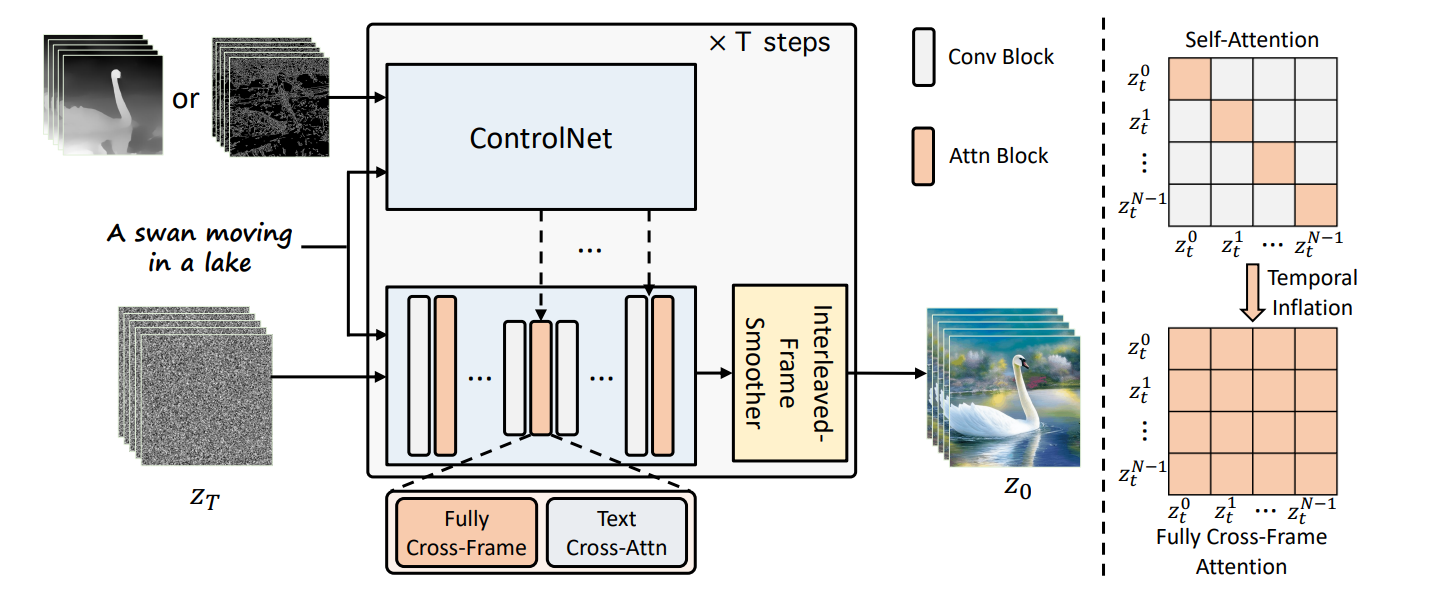
3.1 Fully cross-frame interaction
把一个视频的若干帧拼成一个大图
将SD的Unet在时间维度上展开AlignYourLatents应该也是这样做的,直接将
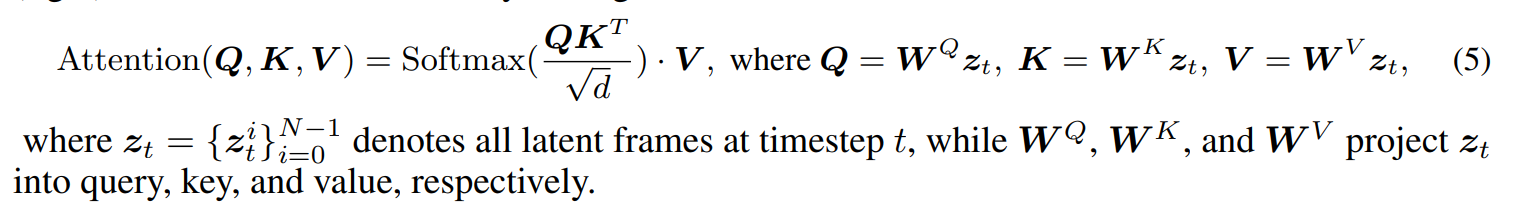
通过高效的实现,这个方法只会带来很小的额外开销
3.2 Interleaved-frame smoother
!picture/Pasted image 20240418152831.png
在两个时间步中,分别对奇数帧和偶数帧进行插值得到中间帧。这样做有两个好处
(i) 新的计算负担可以忽略不计,
(ii) 接下来的去噪步骤能很好地保留插值帧的个性和质量。
3.3 Hierarchical Sampler
层次化的采样解决生成长视频的时候的时间一致性和资源消耗问题:
- 通过将长视频拆分成短视频来一一生成
- 将长视频等间隔取出关键帧组成一个子序列
- 在关键帧子序列上用3.1方法生成视频
- 然后用头尾关键帧生成补全中间的视频
4 Experiment

4.1 Dataset
- 数据集选择:使用了DAVIS数据集中的25个以物体为中心的视频。
- 人工标注:对这些视频的来源描述进行了人工标注。
- 自动生成编辑提示:利用ChatGPT自动生成了与每个源描述相对应的五条编辑提示,总共生成了125对视频提示对。
- 边缘和深度图的估计:为了形成评估数据集,使用了Canny算法和MiDaS DPT-Hybrid模型来估计源视频的边缘和深度图。
- 评估数据集的形成:通过上述步骤,形成了125对动作提示,这些将作为评估“ControlVideo”的评估数据集
4.2 Metric
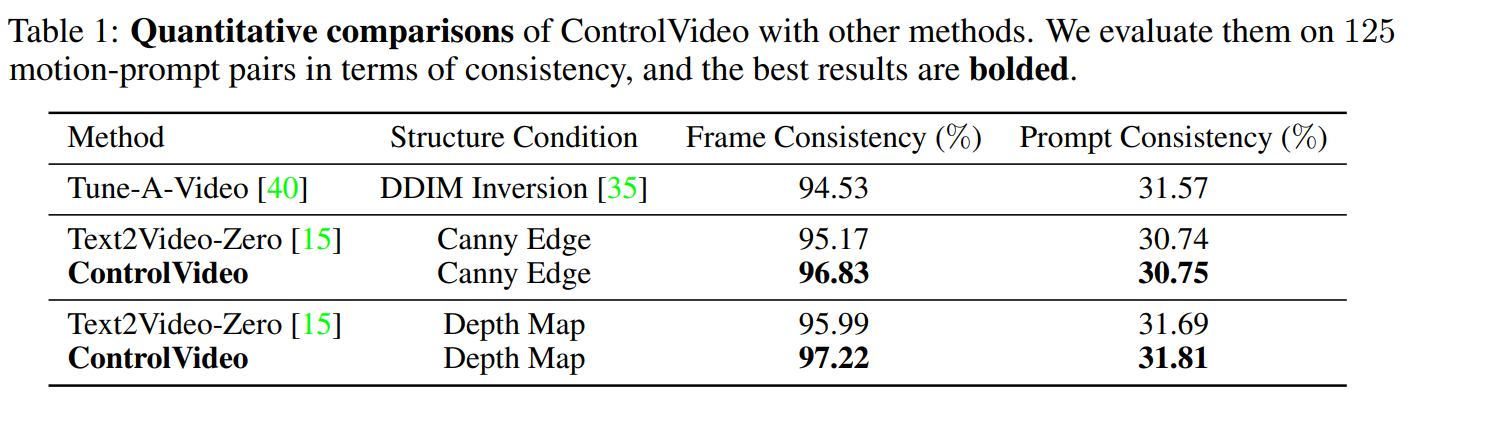
用clip分别计算
- 连续帧之间的余弦相似度
- 图文余弦相似度
5 Summary
这篇工作提出了一种不需要训练的基于ControlNet的视频生成方法。 首先将ControlNet的注意力层中,将输入改成所有视频帧链接起来的编码结果,来解决视频在时间维度上的一致性问题。 然后在去噪阶段,采用了间隔帧平滑的技术在常数级别的开销增加下提高模型生成的一致性。 最后通过层次化生成的方式,先生成关键帧,再补全关键帧之间的视频的方式来提升了模型生成长视频的能力。 最后在边缘和深度图的额外条件下测试了模型的一致性,生成效果,取得了SOTA的效果。
6 Comments
- 这个工作的出发点类似AlignYourLatents,都是利用SD模型
- 3.1 3.2 是比较新的做法,但是3.2节的方法应该可以有更详细的说明
- 3.3节的方法在LVDM里面也有用到
这个Training free manner还挺有启发性的。
- 3.1节只是改了Unet里面的QKV,不需要新的网络
- 3.2节没有网络不需要训练。
- 3.3是层次化生成策略,也没有额外网络
那这样看起来这个工作算是非常有趣