DynamiCrafter
1 Introduction
之前的视频生成工作大多关注自然风景的随机移动或者特殊的人体动作,在其他方面的生成能力有限,所以本工作提出一种可以在open-domain images上生成图片的方法。
他们的工作的目标是在T2V模型上加入一个额外的条件。 要实现这个目标的难点是解决视觉信息理解和细节保存。这个工作属于text2video-> multi-model controllable generation,小领域的主要参考文献是: VideoComposer 和I2VGEN-XL.
To address this challenge, we propose a dual-stream image injection paradigm, comprised of text-aligned context representation and visual detail guidance, which ensures that the video diffusion model synthesizes detail-preserved dynamic content in a complementary manner.
注意到controlNet也是可以用来增加条件的。
clip x
text-aligned rich context representation space using a query transformer. √
2 Related Work
2.1 Image Animation
GAN,Diffusion等方法都用于尝试进行图片的驱动。
2.2 Video Diffusion
Video Diffusion可以被分为Image2video和Text2video两个任务。
在visual condition方面VideoDiffusion还值得被探索。
3 Method
3.1 Video Diffusion
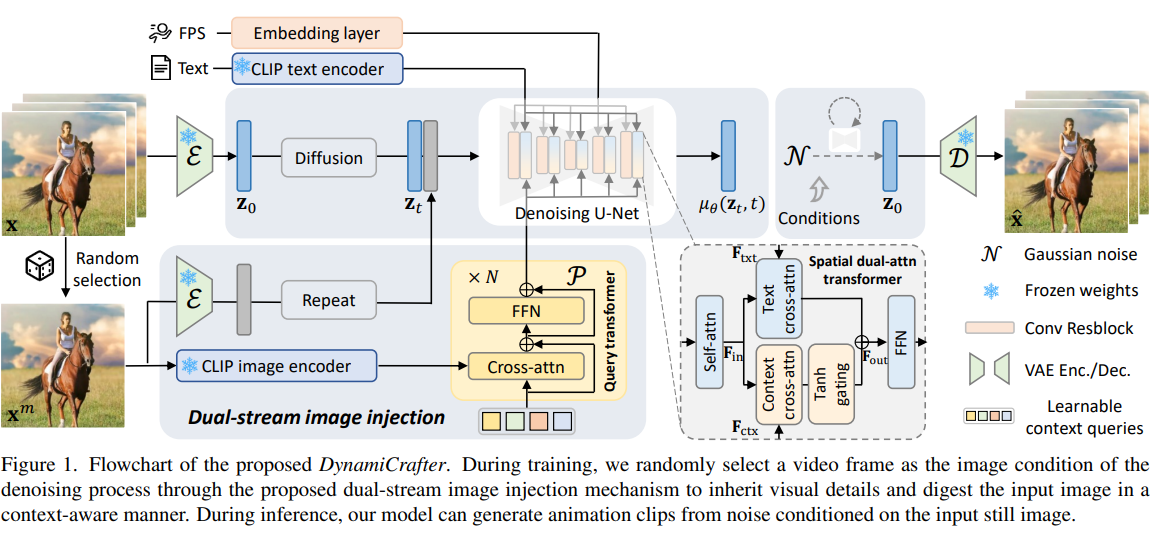
基于VideoCrafter的框架, 将每个视频逐帧编码到隐空间,在隐空间上进行加噪去噪,然后用VAE Decoder进行重建。
3.2 Image Dynamics from Video Diffusion Priors
这一节主要解决如何利用T2V模型先验将单张图片里面的动态信息全面的加入生成的过程。
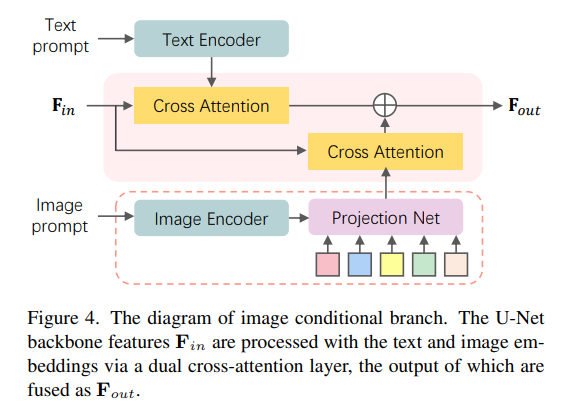
- 用CLIP Image VIT的最后一层特征过一个Query Transformer得到一个视觉特征,下标记为ctx
- 这个视觉特征通过Tanh层和文本特征融合起来
这里的
3.2.1 Visual Detail Guidance
为了让图片更加的清晰,保留更多的细节,作为条件的图片的特征被连接到视频初始的特征上,输入unet,参加去噪过程。
3.2.2 Discussion
text prompt只有semantic level的信息,加入rich context representation(VIT 最后一层的特征) 意味着新的细节的信息被加入了。
3.3 Training Strategy
这个工作同时利用了CLIP Image VIT和VideoCrafter两个预训练模型,在这两个预训练模型中间插入了一个Query Transformer
训练步骤如下:
- 在T2I任务上训练
- 将
迁移到T2V任务上 - 将
和VideoCrafter的时空Transformer层联合训练。
作为条件的图片是随机抽取的,这样的好处是避免过拟合。
4 Experiment
4.1 implementation details
T2I: SD2.1
T2V: videocrafter
用WebVid10M进行训练, 动态FPS
multi-condition classifier-free guidance:
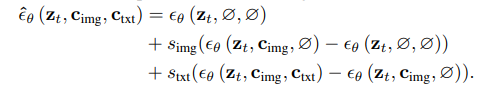
5 Summary
They use a randomly selected image from the video as conditional image. The conditional image in encoded by VAE and concatenated to initial video feature. The conditional image is also encoded by CLIP image VIT to add rich context representation in the Unet. The image context representation is blended with text representation using Tanh layer. The experiments shows the model based on VideoCrafter is solid and the results are promising.
他们使用从视频中随机选取的图像作为条件图像。条件图像由 VAE 编码,并与初始视频特征相串联。条件图像也由 CLIP 图像 VIT 编码,以在 Unet 中添加丰富的上下文表示。使用 Tanh 层将图像上下文表示与文本表示混合在一起。 实验结果表明,基于 VideoCrafter 的模型是可靠的,效果也很好。
6 Comments
However, it is a pity that no more experimental results to prove the open-domain ability proposed before.
但遗憾的是,文中提到的open-domain ability没有更多的实验结果来证明。
增加在CLIP image encoder后面的轻量级query transformer可以被看做是一种PEFT,插入到原来的Unet里面。
这里通过一个
本文中提出的问题,即给视频生成的过程中加入更加丰富的图片信息,比语义信息更加细粒度的信息是值得被继续探索的。
6.1 a small detail