EvalCrafter
1 Introduction
在视频生成上常见的的IS和FVD不能展示模型全面能力。 所以需要一种能够全面衡量模型能力的指标。 作者基于对真实世界的用户数据的分析构造一个包含700个提示词的数据集来做text-to-video的评估。 首先设计一系列常见的prompt,用LLM进行扩充。
评价的内容包括:
- video visual quality 视频质量
- video motion quality 动作质量
- video temporal consistency 时间连续性
- text-video alignment 文字和视频的对齐
2 Related Work
2.1 Text-to-Video Evaluation
之前的工作的主要指标有: FVD,IS和CLIP-score。 利用预训练的VAE,GAN等模型会存在低质量和领域限制的问题。 全面的对Text-to-Video的模型进行评价有利于后续工作的开展。
2.2 Evaluations on Large Generative Models
在NLP和视觉领域,对大语言模型和多模态大模型的评估也是研究者非常重视的领域。 现有的方法基于不同能力,不同的问题类型和用户平台进行测试。
在视觉生成领域,一些图片生成工作Imagen,DALL-Eval等会用用户反馈对模型进行评价,或者会使用目标检测等算法。HRS-Bench利用ChatGPT生成Prompt在多个指标上评价Text-to-Image模型。 TIFA使用了VQA任务进行评价。 除了这些在Text-to-Image上有效的评价指标外,我们还考虑了对Text-to-Video增加动作质量和时序连贯性评估。
3 Method
3.1 Real-World Data Collection
为了更好的了解真实世界中产生的prompt的分布,作者从FullJourney和PikaLab的数据集里面提取了Prompt。 然后对这些Prompt进行分析和处理。 得出了一些分析结论:
- 主语分为四类: human,animal, object,landscape
- 对每个主语定义motion和style
- 定义主语之间的联系
- 定义camera motion
3.2 General Recognizable Prompt Generation
prompt数据集自动化的生成方式是:利用之前提取到的类别和属性信息,通过随机抽取meta info的方式让GPT-4构造prompt,然后让GPT-4自己检查prompt的一致性等质量。 最后加入人工筛选和人工生成的Prompt。
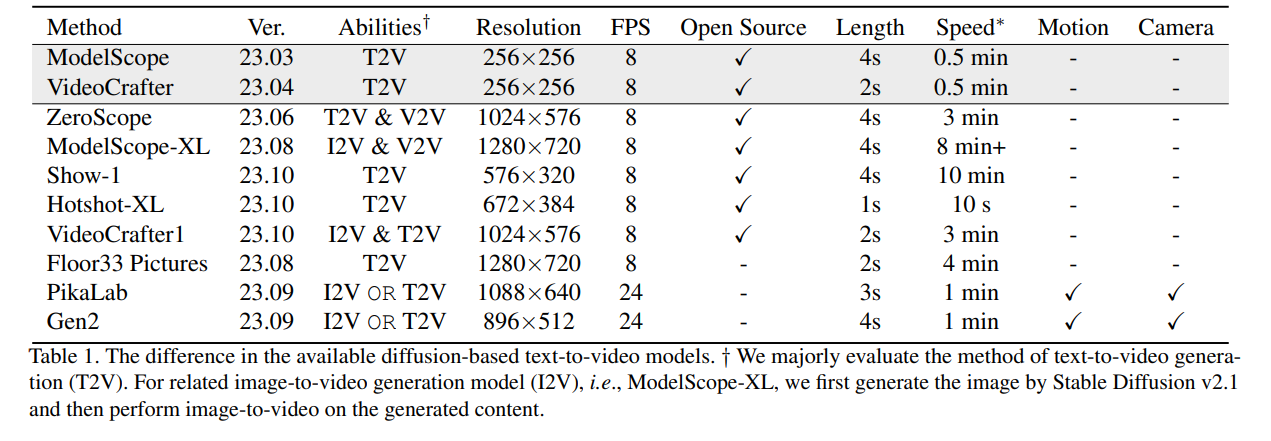
4 Evaluation Metrics
4.1 Overall Video Quality Assesment
Video Quality Assessment(
IS 用ImageNet上训练的Inception Network的特征进行评价。
4.2 Text-to-Video Alignment
Text-Video Consistency(CLIP-score). 对每一帧都计算一个CLIP-score然后求平均值。
Image-Video Consistency(SD-score). 现在的视频生成模型大多基于SD进行微调,所以他们将视频的每一帧的质量和一个frame-wise SD生成图片计算相似度。
Text-Text Consistency (BLIP-BLEU). 用BLIP2对视频生成描述,然后再用BLUE计算图片相似度。
Object And Attributes Consistency.
- Detection-Score. 用Detection Model对一个视频的若干连续帧进行检测,用来评估一个物体能被检测到的帧数的均值。
- Count-Score. 计算Prompt中提到的物体能够被检测到的比例。
- Color-Score. 对有颜色描述的物体的颜色匹配程度进行检查,计算平均匹配率。
Human Analysis(Celebrity ID score). 用DeepFace对生成的人像进行检测
Text Recognition(OCR-score).为了检测T2V models在text generation方面的能力。用paddleOCR检测,
可不可以把TextDiffuser扩展到这个T2V上面来
4.3 Motion Quality
Action Recognition. 利用VIdeoMAE等模型对人的动作进行识别。
Flow Estimation. 对一般的物体的运动,利用RAFT做dense flow estimation来计算视频的平均光流效果。
Amplitude Classification Score. 评价光流是否和文本描述中的一致。
4.4 Temporal Consistency
Warping Error. 利用光流估计的预训练模型对视频计算像素级别的变化程度。
CLIP consistency. 两帧之间的CLIP embedding的余弦相似度。
Face consistency. 利用人脸识别的预训练模型计算帧间余弦相似度。
5 Results
5.1 Analysis on Human Preference Alignment
做了Spearman's rank correlation coefficient 和 Kendall's rank correlation coefficient显示他们指标和人类指标的相关性比之前的单一指标例如CLIP更好。
5.2 Findings
发现 #1: 单维度评估对现今的T2V模型不足
在表中,模型的排名在不同方面上有显著变化,强调了多方面评估方法对于全面了解模型性能的重要性。
发现 #2: 元类型评估的必要性
模型在各种元类型下表现不同,强调了按元类型评估其能力的重要性。例如,Gen2在human、animal和style视频的VQAlandscape、object和realistic视频中落后。
发现 #3: 用户优先考虑视觉吸引力
尽管Gen2在T2V对齐方面表现相对较差,但在主观相似度方面超越了其他模型,表明用户更偏好视觉吸引力强的视频。
发现 #4: 相机运动控制的限制
当前的T2V模型缺乏使用文本提示直接控制相机运动的功能,尽管某些模型具有用于控制的附加超参数。
发现 #5: 分辨率与视觉吸引力
分辨率与视觉吸引力之间的相关性不强,低分辨率模型表现优异的案例证明了这一点。
发现 #6: 用户对运动幅度的偏好
用户更喜欢具有轻微运动的视频,而不是运动过度的视频。
发现 #7: 文本生成的挑战
大多数方法在从提示生成高质量和一致性文本方面存在困难,如OCR-Scores所示。
发现 #8: 模型失败案例
某些模型偶尔生成完全错误的视频,可能是由于灾难性遗忘问题引起的。
发现 #9: 有效和无效的评估指标
某些指标(如Warp Error、CLIP-Temp、VQA
发现 #10: 当前模型有改进空间
尽管取得了一些进展,但当前的T2V模型在处理复杂场景、遵循指令和描绘实体细节方面仍有较大改进空间。