Follow Your Click
1 Introduction
1.1 Problem Statement
Using user click to animate video from input image.
Control ability and local animation in video generation.
Aims to simplify control condition by user click and motion prompt.
通过用户点击来动画化输入图像,并具有对视频生成过程中控制能力和本地动画的控制能力。旨在通过用户点击和运动提示来简化控制条件。
1.2 Stated Contribution
-
the first to support click and motion prompt
-
first-frame masking ; motion-augmented module ; short prompt dataset ; flow-based motion magnitude
-
extensive experiments and user studies to show achievements
-
首个支持点击和动作提示的模型
-
首次帧掩码;动作增强模块;短提示数据集;基于流的动作幅度
-
大量实验和用户研究展示成果
2 Related Work
2.1 Text-to-Video Generation
目前有很多种不同的方法做Text-to-Video Generation的control. 包括但是不限于: depth, image, key points等等。
2.2 Image Animation
从输入图片生成视频,保持原有图片的特征的同时有足够好的动作质量。
新一点的方法有: dynamicrafter,livephoto等基于diffusion的方法,还有I2V-adapter基于plug-and-play的方法。
Gen-2和animate anything可以通过motion mask的方式让用户实现对图片的编辑,但是这种交互方式对用户不如点击-拖动的方式友好。
3 Method
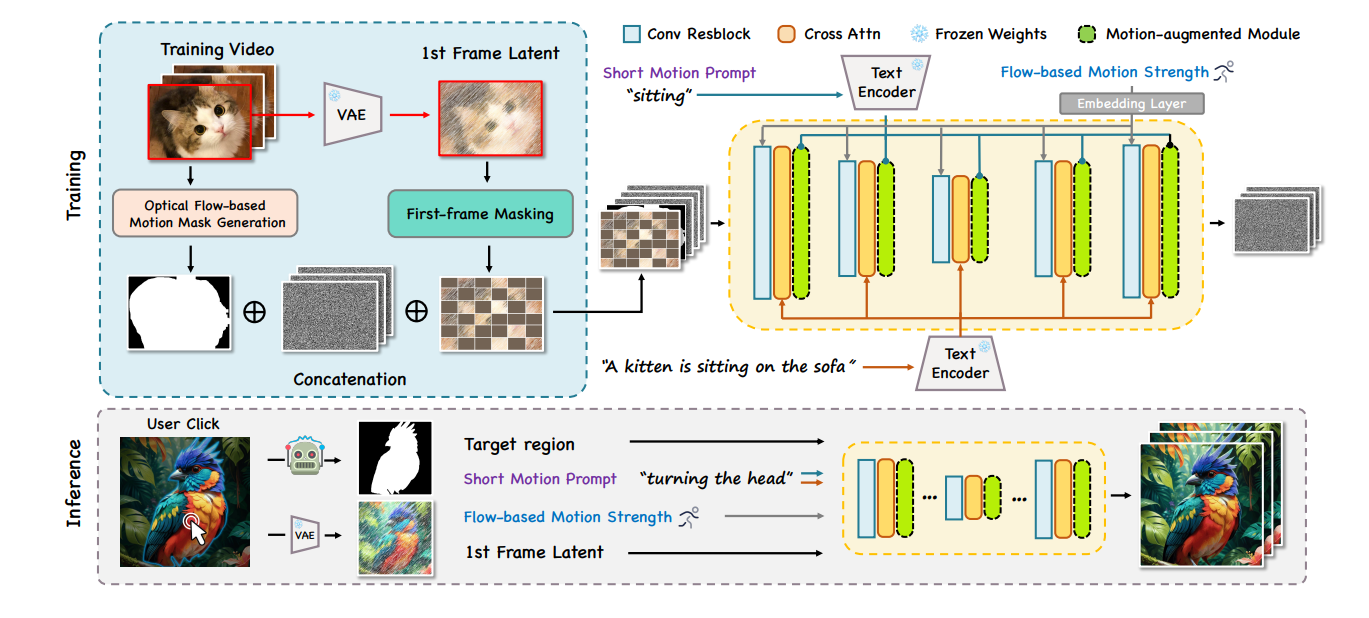
3.1 Preliminaries: LDM and VDM
借鉴了AnimateDiff方法,我们将预训练的图像潜态扩散模型(LDM)转变为时序到视频(T2V)模型。在这一过程中,我们通过插入时序动作模块,并冻结原有参数,来进行训练。这些时序动作模块包含一维时间注意力,在每个空间模块之后插入,主要负责捕获不同帧间同一空间位置表示之间的时间依赖关系。
3.2 Follow Your Click
3.2.1 Problem Formulation
输入:
- image
- click
- motion prompt
输出: - video
问题拆分: - 被编辑的局部生成质量
- 动作提示词的控制质量
- 动作幅度的控制质量
对原图片的修由click提供目标物体,由prompt提供移动模式。 通过SAM模型来对图片进行高质量的分割,得到一个mask M。 然后基于这个mask可以确定需要被编辑的物体。
3.2.2 Regional Image Animation
Optical flow-based motion mask generation. 作者利用预训练的光流预测网络来自动生成视频中移动物体的掩码。 每一帧得到的移动物体掩码组合起来可以表示动作的幅度。 在训练阶段用最后一帧的掩码作为动作区域的真实值。 在测试阶段用SAM把click转换成motion mask。
First-frame masking training. 把第一帧的mask下采样,再编码之后,和噪音链接起来。 DynamiCrafter,Make-Your-Video都用了这种链接方式。
我们采用了v-预测参数化方法进行训练,因为在少量推断步骤时,它具有更好的采样稳定性。
3.2.3 Temporal Motion Control
Short motion caption construction. 我们发现WebVid等数据集中的标题通常包含大量场景描述性术语,而较少涉及动态或运动相关的描述。为了实现更好的短提示动作控制能力,我们构建了WebVid-Motion数据集具体来说,我们构建了50个样本,以实现GPT4的上下文学习。每个样本包含原始提示、对象以及它们的简短动态相关描述。这些样本以JSON格式输入到GPT4中,然后我们向GPT4提出相同的问题,以预测WebVid-10M中的其他短动作提示。最后,重新构建的数据集包含标题及其与动作相关的短语,例如“转头”,“微笑”,“眨眼”和“跑步”。我们在这个数据集上对我们的模型进行微调,以获得更好的短动作提示跟随能力。
Motion-augmented module. 插入新的motion-block来处理motion相关的prompt、
Optical flow-based motion strength control. 动作强度和FPS的关系不是线性的,所以需要对FPS进行改进。 在SAM得到的motion区域里,利用光流计算区域内的平均规模,然后把规模投影位置编码,再加入每帧的残差块里面,保证所有帧的动作嵌固端。
4 Experiment
4.1 Implementation Details
- 实验中使用了稳定扩散(SD)V1.5作为空间模块,以及相应的AnimateDiff V2作为动作模块。
- 在训练过程中,冻结了SD图像自动编码器,以便对每个视频帧单独进行编码。
- 在WebVid-10M上进行了60k步的模型训练,并在重构的WebVid-Motion数据集上进行了30k步的微调。
- 训练视频的分辨率为512×512,每个视频包含16帧,步幅为4。
- 使用8块NVIDIA A800 GPU进行了三天的Adam优化,批量大小为32。
- 学习率设置为1 × 10^−4,以获得更好的性能。
- 训练过程中,第一帧的掩码比例为0.7。
- 在推断阶段,采用了DDIM采样器和无分类器的指导,缩放为7.5。
4.2 Comparison Results
现有模型的问题:
- SVD 和 Dynamicrafter 生成的视频展示出对语义的理解不足,和初始帧差距较大
- I2VGen-XL 平滑的动作,缺少视频细节
- Genmo对动作提示词不敏感
- Animate-anything 对动作的感知和修改效果很好,但是对文本理解不到位
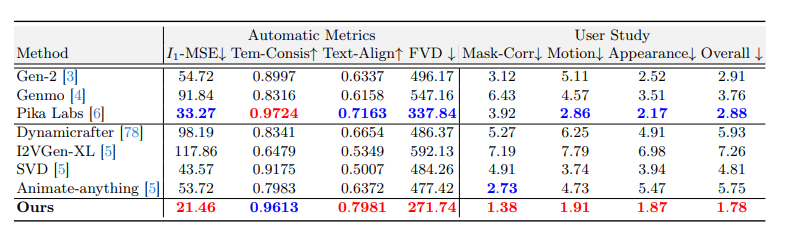
评价指标包括: - I-MSE第一帧和输入帧之间的MSE
- Tem-Consis 帧间CLIP相似度
- Text-align 动作提示词和图片匹配度
- FVD: 视频质量品谷识别表
- 用户对修改部分和输入的匹配度评价,生成视频和第一帧之间的连续性,整体视频效果
5 Summary
利用SAM模型将用户的点击转换成表示动作的mask作为额外条件来训练驱动一张图片生成视频的扩散模型。 构造了一个基于webvid的数据集,重新标注了描述词,着重增加了对于动作的描述,用光流估计预训练模型得到动作的起始和结束为止分别作为条件和监督信号。 用视频motion平滑的方法让模型对FPS产生感知,避免模型生成的模型不均或者过小。
6 Comments
- 太奇怪了 这个居然没引用DragGAN
- 把一个特征链接到加完噪音的地方一起去去噪 有用 多篇论文证实
- 重新生成caption、重新筛选数据集