Follow Your Pose
1 Introduction
本文关注到了人物动作这一子类的视频生成,认为缺乏视频-动作描述和先验导致了这类视频生成的落后。 所以这个工作设计了一个两阶段训练模式,利用image-pose pair数据集和pose-free video数据集训练pose-controllable T2V model.
他们用了controlnet的zero-convlution在image-pose 上训练了一个模型。 然后在里面插入新的时序层来学习时间一致性。
1.1 Stated Contribution
- 提出pose-controllable text-to-video任务和LAION-Pose数据集
- 用两阶段训练分别解决pose-alignment和temporal coherence两个问题
- 实验证明了他们的工作的效果
2 Related Work
2.1 Text-to-Video Generation
pass
2.2 Pose-to-Video Generation
Vid2vid: conditional GAN + 光流估计 + 时序一致性限制 + 多判别器
few-shot Vid2vid: 用少量例子来驱动一张输入图片
FOMM & FRAA(2021) : 提出新的pose表征方法
他们都没有高效利用文本编辑视频的能力
2.3 Controllable Diffusion Models
利用额外的信息(depth,key points, segmentation map)来控制图片生成。
3 Method
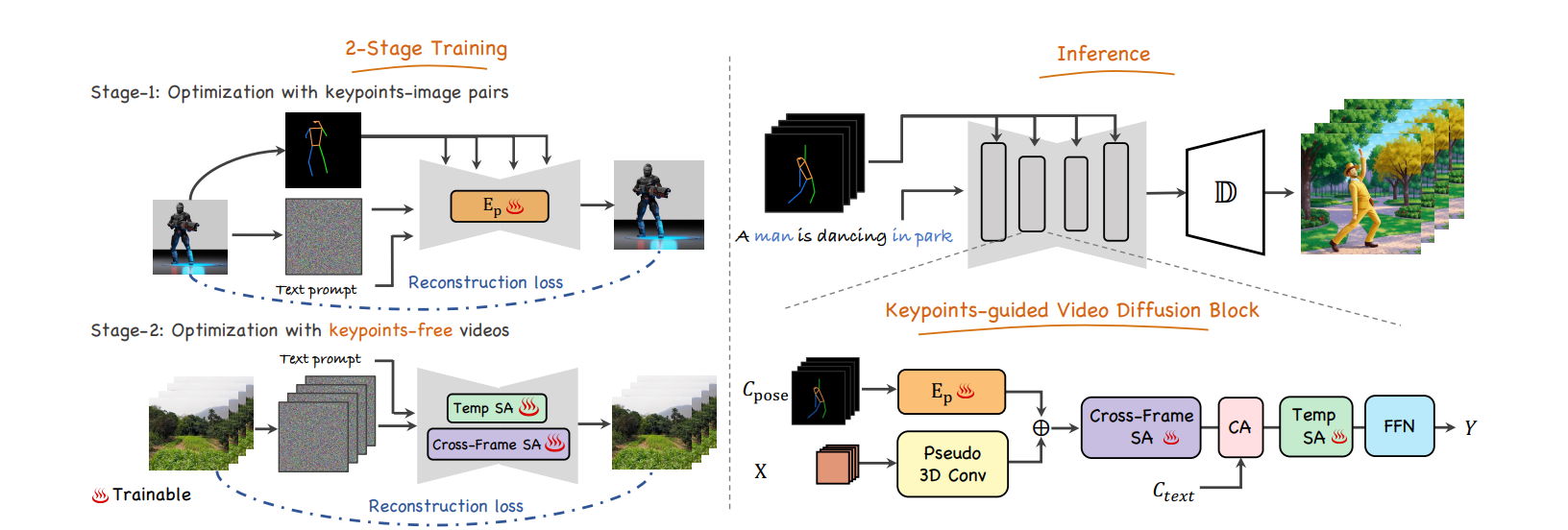
3.1 Latent Diffusion Model
还是我们熟悉的方法,熟悉的写法。
扩散模型通常由两个过程组成:前向扩散和逆向去噪。 给定输入信号
3.2 Pose-Guided T2V
这个工作是基于text-to-image的预训练模型做的。
3.2.1 Stage 1: Pose Controllable Training
- 首先用MMpose在LAION数据集上得到关键点,只保留50%以上检测到的,构造出LAION-pose数据集
- 冻住原来的Unet的所有参数,然后插入3D conv组成的轻量网络作为pose encoder,通过残差方式将特征插入。
3.2.2 Stage 2: Pose Free Video Training
- 展开卷积核 得到一个pesudo-3D Unet
- 插入时序注意力机制
- 增加帧间注意力机制
- 做长视频生成的时候重用DDIM采样结果
4 Experiment
4.1 Implementation Details
- Stable Diffusion 做backbone
- 用LORA
- Stage1 100k Stage2 50k step
- 8
40GA100

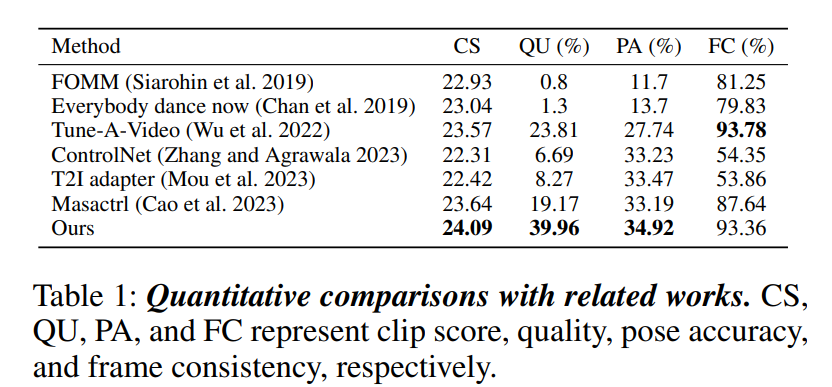
4.2 Quantative Result
5 Summary
基于T2I的预训练模型,通过插入pose encoder和SA等网络将T2I转变成了一个可以控制pose的视频生成模型。 作者用了类controlnet提出的zero-convution来初始化条件控制,通过插入SA和cross-frame SA来提升连贯性。 除此之外,重用DDIM采样结果来作为视频后续帧的先验。 实验结果上,在CLIP score,pose acc, frame consistency上超过了之前的方法。
6 Comments
- 重用DDIM采样结果的方法挺好 回头看看怎么实现的
- 插入注意力机制和帧间注意力已经有很多论文提到了 之后记得对比一下
- 和DynymicCrafter和make a video的控制方法不一样 和ControlNet更接近