Latent Video Diffusion
perturbation : 扰动
mitigate: 缓解
1 Introduction
1.1 Problem Statement
视频生成是一个长期未能解决的困难任务。 对内容生成,游戏,电影行业有非常重要的意义。
自回归的视频生成会随着长度增加有质量下降的问题。
1.2 Related Work
现有的方法:GAN; AR model; normalizing flows
GAN: 模式坍塌,训练不稳定,因而难以扩大
DMs可以扩大,但是有计算资源限制。
1.3 Claimed Contribution
Key Design:
- utilizing a low-dimentional 3D latent space
- hierarchical diffusion
- conditional latent perturbation 和 unconditional guidance
从这第三点来看 应该和Classifier Free Guidance的方法有关。
Contribution:
- efficient extension
- long video generation
- mitigating accumulated error
- state-of-the-art results and open source
2 Method
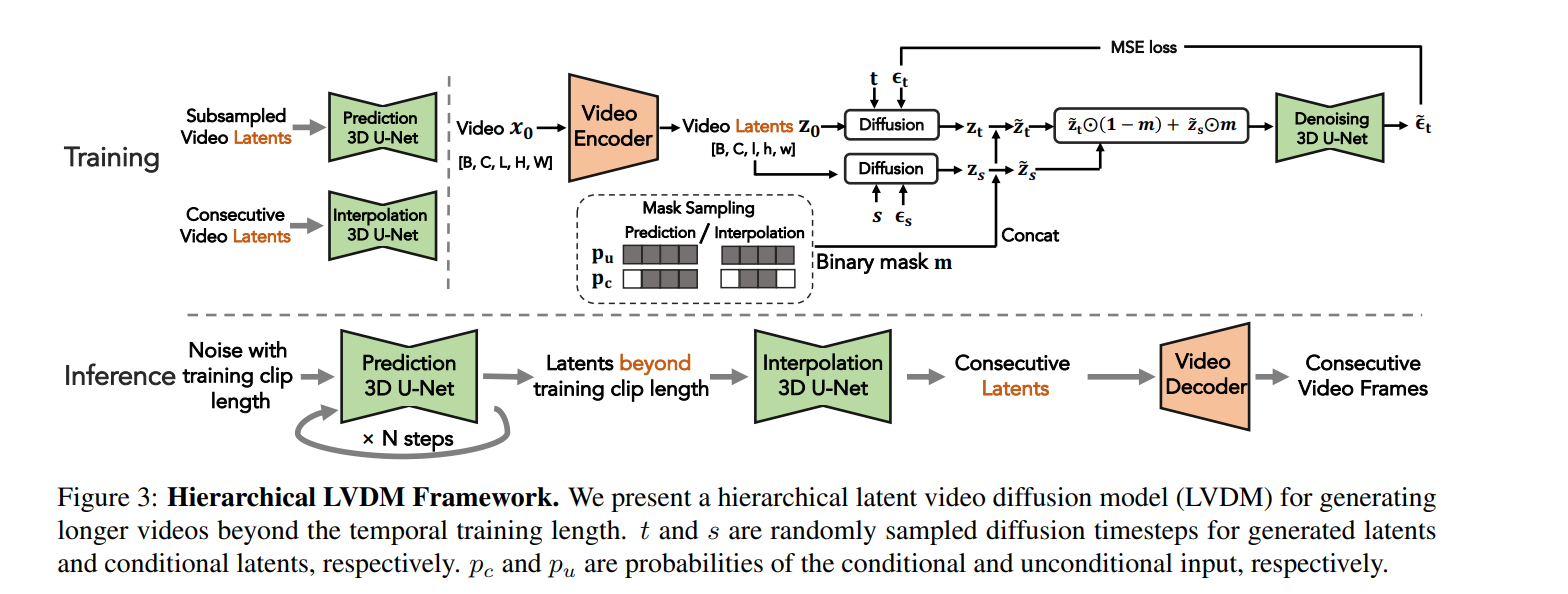
首先将视频压缩到低维空间;
设计一个同时支持conditional和unconditional的diffusion;
稀疏生成关键帧,在进行隐向量插值。
2.1 Video Autoencoder
轻量级的只包含几层3D conv的自编码器,三个方向都采用repeat padding
训练损失函数:
包含1. MSE 2. LPIPS loss 3. adversarial loss
2.1 Base LVDM for Short Video Generation
LVDM:= Latent video diffusion model
Latent:= 对隐向量latent vector添加噪音,而不是直接对image或者video添加噪音
Video Generation Backbone. 3D U-Net需要考虑一维时间和二维空间信息(spatial-temporal factorized)。在kernel为
这些attention是怎么设计的之后再来讨论。
除此之外,增加adapative group normalization对生成质量是有帮助的。
2.2 Hierarchical LVDM for Long Video Generation
用自回归的方式对2.1里生成的short video的latents进行扩展。
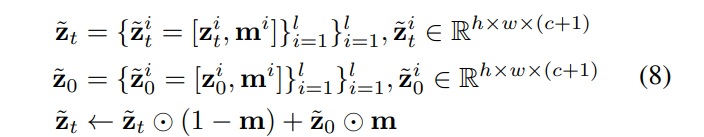
m是随机采样的掩码,保证conditional和unconditional同时训练。
Hierarchical Latent Generation. 一个模型负责预测稀疏的视频帧,另一个负责补全两帧之间的间隔。
Conditional Latent Perturbation. 对第
Unconditional Guidance. 方法来自Classifier Free Diffusion Guidance,但是似乎没有这个方法为什么可以解决degradation of autoregressive video generation的推导。
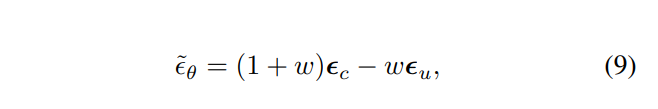
3 Experiments
训练时间: 8卡V100 4.5days
在同样的训练资源下,LVDM有更好的效果,更高的效率,和几乎一样的参数量。
3.1 Dataset
dataset:
UCF101: full
Skytime-lapse training split
Taichi: full
item: random location with stride frame
resolution: 256
strategy : both conditional and unconditional guidance
3.2 Metric
FVD: fréchet video distance, 将FID的网络换成3Dresnet
KVD: 基于Inflated-3D Convnets使用最大均值差异(MMD),一种核方法来评估生成视频的质量
3.3 Baseline
GAN-based method:
TGAN-v2
DiGAN
MocoGAN-HD
long-videoGAN
Diffusion-based method:
VDM : implemented by the author
MCVD
3.4 Training details
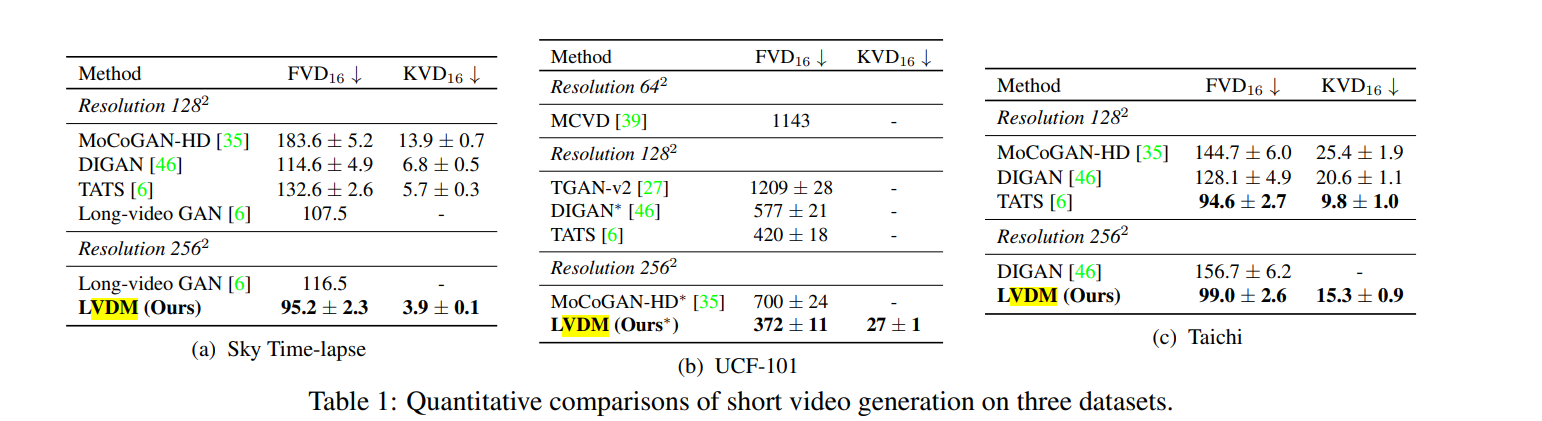
在短视频生成上,LVDM效果相对于其他方法有断崖提升
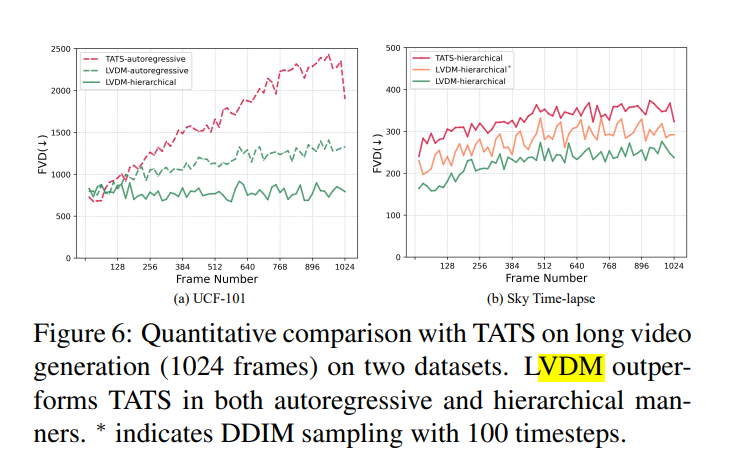
在长视频生成上,hierarchcal的结构有利于缓解生成质量下降的问题。
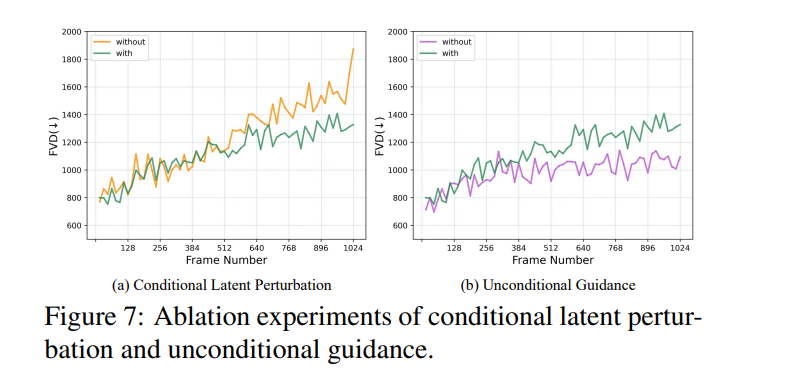
消融实验证明Conditional Latent Perturbation 和Unconditional Guidance在512帧以后的生成效果上有显著效果。
4 Comment & summary
- 每一个方法有一个明确的需要解决的问题。
- AE做出了针对video的调整
- diffusion主要解决长距离效果下降的问题
4.1 previous work
- normalizing flows