Latte
Latent Diffusion Transformer for Video Generation.
将Transformer和Diffusion结合起来。
1 Introduction
首先考虑CV领域正在发生变化的模型架构。 Unet是基于CNN构建的,在图片和视觉生成领域占据主导地位。 但是DiT,UViT等基于ViT的架构正在逐渐和Diffusion Model结合起来,并且在图片生成领域取得了不错的效果。 Attention机制在捕捉视频的上细纹信息方面可能会有帮助。
这篇工作提出了Latte,一个基于Video Transfomer的模型。 先用预训练VAE提取特征,再用若干Transformer编码这些特征。 在解耦时间空间特征的方面,我们设计了四种不同的变体来处理视频。
做了一系列分析和实验,包括video-clip patch embedding , model variants, timestep class information injection, learning strategies.
2 Related Work
2.1 Video Generations
GAN-based method , DIffusion-based methods. etc.
2.2 Transformers
3 Method
!picture/Pasted image 20240414205751.png
3.1 Preliminary of Latent Diffusion Models
在训练的过程中模型同时应用了
模型首先将视频逐帧编码成Token,然后给Transformer对逐帧编码的隐向量建模时间和空间信息。
3.2 The model variants of Latte
作者探索了四种不同的Transformer变体来捕捉时间和健信息。下面我们把ST和TT分别作为Spatial Transformer和Temporal Transformer的记号。
ST和TT间隔版本
考虑一个视频
一个时空位置编码p和z相加之后得到放入Transformer的隐向量
把token放入ST的时候,需要将H,W合并成一个维度,来计算空间信息,放入TT的时候则将HW提到第一个维度,来计算时间信息。
先ST再TT顺序版本
利用Late fusion技术结合时间和空间信息。 这个版本和上一个版本拥有相同的Transformer Block数量。 也类似的需要做维度合并来提取时空信息。
后面两个在Attention-level做改进
顺序Attention时间空间信息
先用一个self-attention提取时间信息,再用另一个self-attention提取空间信息。
同时Attention时间空间信息
用一个MHA的一半的注意力头提取时间信息,另一半的头提取空间信息。
3.3 Empirical Analysis
Video Clip Patch Embedding
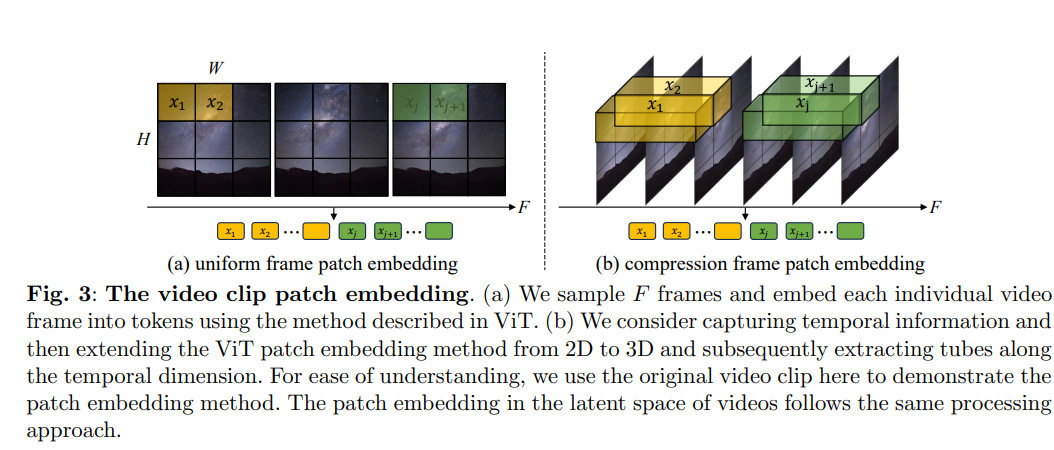
作者尝试了两种Embdding方法来抓取Video Token. 第一种是简单的扩展ViT的Token提取方法,逐帧提取Token. 第二种是将2D卷积核扩展到3D卷积核。 (应该是这样,因为ViT的Token提取就是依靠一个不重叠的卷积层实现的)
从直觉上来说,后面一种是更加合理的。
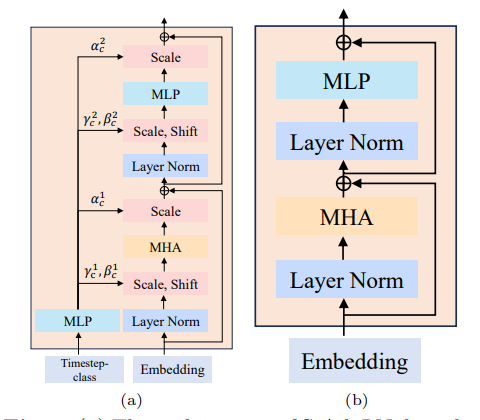
Timestep-class information injection
第一种叫做All tokens:把帧数也计算成Token; 第二种是 Adaptive layer normalization. 这个normalization的方法负责计算一个缩放的系数乘在每一个Layer后面。
Temporal Positional Embedding
- 绝对位置编码,不考虑FPS
- 相对位置编码,考虑后继帧之间的时间关系,就是对FPS有感知
Training Strategy
用预训练模型辅助训练。 初始化为一个DiT,根据之前的方法实现了位置编码等改进。
图片和视频数据联合训练。 之前的工作Stable Video Diffusion,VideoCrafter都是有用这个策略的,所以检验了一下在Transformer backbone上是否有效。 直觉和实验都证明了是有效的。
4 Experiment
四个数据集 FaceForencis, SkyTimeLpase,UCF101, Taichi
Video的方法比LVDM好一点。
VAE用的SD1.4
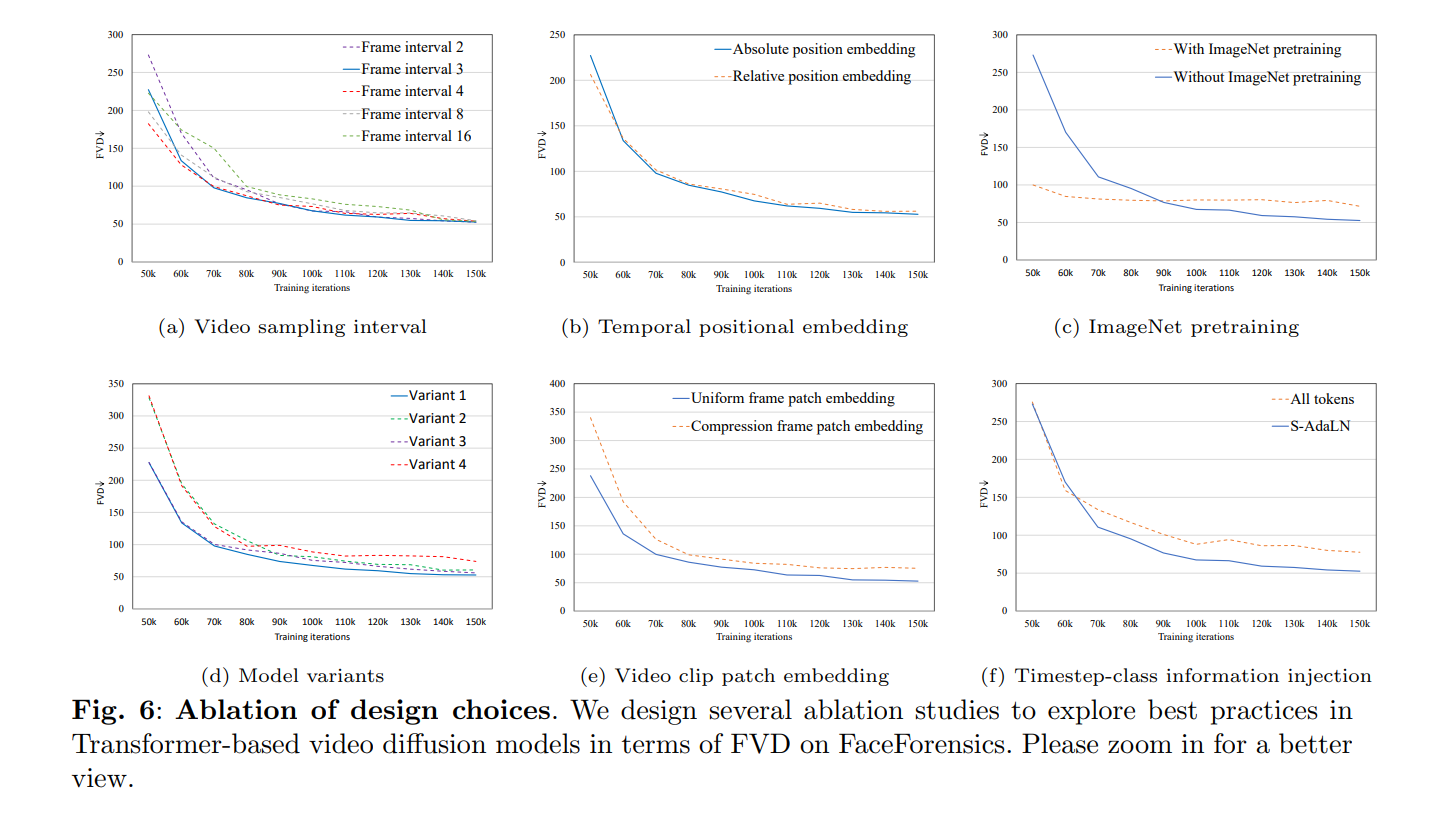
4.1 Findings
- 采样间隔对最终FVD效果没什么影响,但是会影响收敛速度
- 时间位置编码几乎不会带来FVD的差异。(个人认为有待进一步分析)
- ImageNet Pretraining会显著提高FVD稳定性,但是最终效果反而不好
- 四个变体没有显著差异,第四个变体略差。
- 3D卷积核提取的Token效果更好
- AdaLayer的效果更好,训练速度也更快
- Transformer越大效果越好
5 Summary
作者将
6 Comments
这个工作考虑了非常全面的问题。
- FPS会不会影响模型的生成效果。
- image-video 联合训练
如果这个工作不是恰好在且仅在LVDM之后,那应该多比其他Diffusion Video Model.