MagicTime
1 Problem Statement
这个工作的主要动机是解决T2V模型真实物理知识不足的问题。 作者认为物理知识的缺乏会影响视频里面物理过程的展示。 例如下图里面展示的种子发芽,鲜花枯萎。 其他经典的物理过程还有云卷云舒,潮汐涨落。 这些都是时间维度上的变化,且和真实世界时间流逝速度不一致,观察种子发芽需要若干天,观察云卷云舒只需要一天。 除了时间维度的变化,还有空间角度的变化,也等价为相机角度的变化。

1.1 Dataset Construction
他们构造了一个ChronoMagic数据集来训练模型。 这个数据集包含很多变质过程的视频: 冰融化成水,鲜花开放等等。 这些视频的特点是:物理知识丰富,一致性强,有变化。
1.2 Stated Contribution
- 一个可以将普通T2V模型转化为可以生成时间压缩视频的MagicAdapter
- 一个动态抽帧策略来高效提取物理过程变化的关键帧和一个对物理变化信息理解能力增强的文本编码器。
- 一个自动的标注物理变化视频的框架,在此基础上构造了2256个视频的数据集
- 大量的证明模型能力的实验
2 Related Work
pass
3 Method
3.1 Dataset Construction
webvid-10M里面包含了大量一致的平常生活的视频,但是却避免了包含物体形变等其他显著变化的视频。 所以这导致了开源模型的一个bias: 不能生成带有明显变化的视频。 所以需要构造一个新的数据集来纠正这个bias.
这里提示: 去看数据集里面的case,去分析里面潜在的问题也是必要的。
3.1.1 Dataset Curation and Filter
数据筛选带来的好处,在Stable Video Diffusion里面有详细的分析。 高质量的数据集会带来模型性能的提升。
数据集是从YouTube上用"time-lapse"做关键词爬的,然后筛除掉标题很短,浏览量低,缺少标签的图片。
3.1.2 Key Frame Detection
用opencv检测pixel intensity,然后计算一个视频的两个连续帧之间的差异,然后将差异大于给定阈值的帧记为关键帧。
从CLIP对视频的连续帧进行编码,然后计算帧间相似性,同样给定阈值,把小于阈值的记为关键帧。
如opencv和CLIP同时把该帧记为一个关键帧,那么这就被认为是一个关键帧。 然后将这些关键帧用于做视频切分。
考虑到这个工作关注本身就带有变化一些物理过程,那么这里关键帧更加偏向镜头切换一类的场景。
3.1.3 Multi-View Text Fusion
用incontext learning和chain of thought的方式引导GPT4V从一个视频的标题,标签,描述等生成一个合适的精确文本描述。
作者认为用多模态模型对关键帧图片进行标注可能会限制视频的标注效率。
3.2 MagicTime
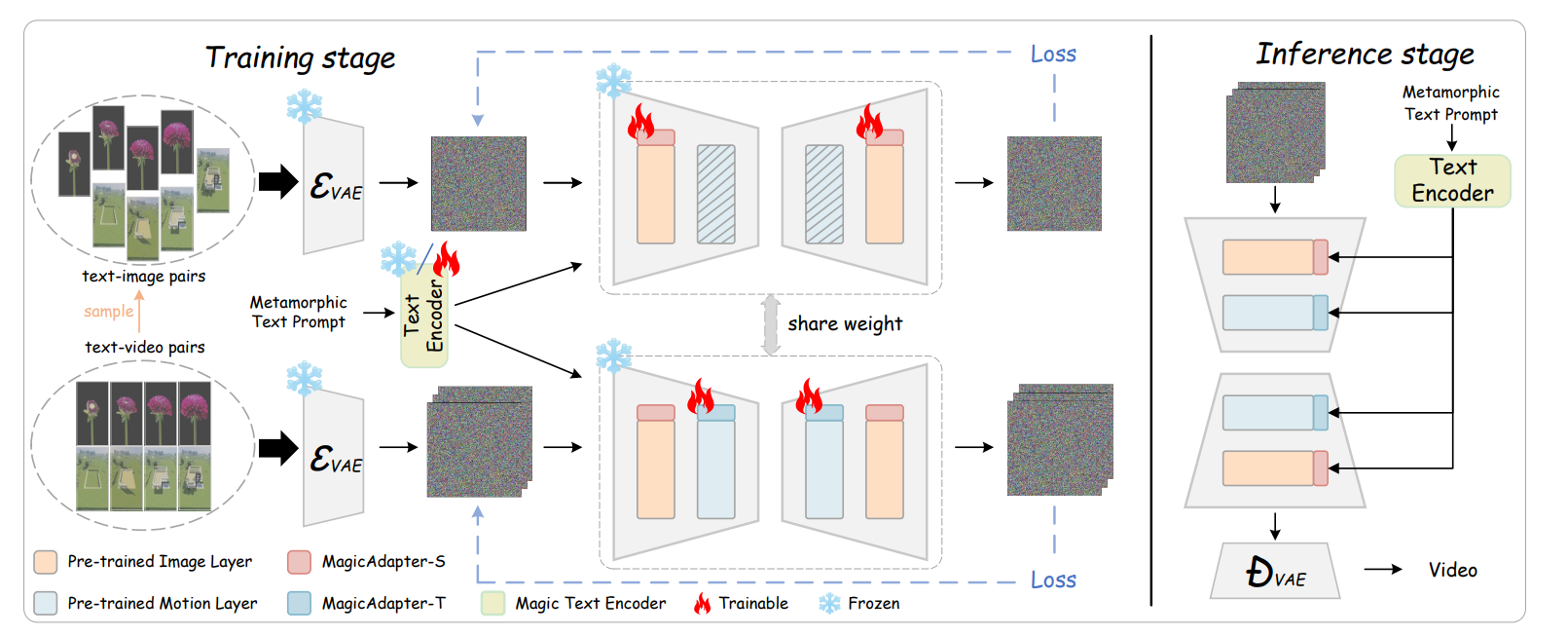
3.2.1 Magic Adapter
网络上爬取的视频带有视频水印,会给模型训练带来额外的困难。 然后他们想要通过分开空间特征训练和时间特征训练的方式来解决这个问题。 让空间模块关注画面中的物体而不是水印。
这个逻辑没太理解
借鉴QLORA-adapter的方法,把时间层去掉之后,他们在空间层里面插入adapter layer,然后用关键帧-文本对数据集进行训练。
在训练时间模块的时候又把时间层加进来了,还要加上新的adapter layer在视频-文本对上进行训练。
3.2.2 Dynamic Frames Extraction
带有物理变化的数据的一个特征就是对时间维度进行了放缩(例如一个开花的视频只有几秒,但是开花的过程长达几天)。 所以随机的采样关键帧进行训练会丢失这种时间属性,因此采用均匀采样来保证时间信息不丢失。
但是均匀采样会有潜在的模型过拟合风险,所以这里采用的按比例进行随机采样和均匀采样。
3.3.3 Magic Text-Encoder
在CLIP的text encoder上加入了lora层来训练对本文提出的数据集的Prompts的理解。 这个被lora微调过的text_encoder可以更好处理包含物理信息的prompt。
4 Experiment
4.1 Evaluation Metric
FID: 比较图片质量
FVD:比较视频质量
CLIPSIM: 文本和图片的一致程度
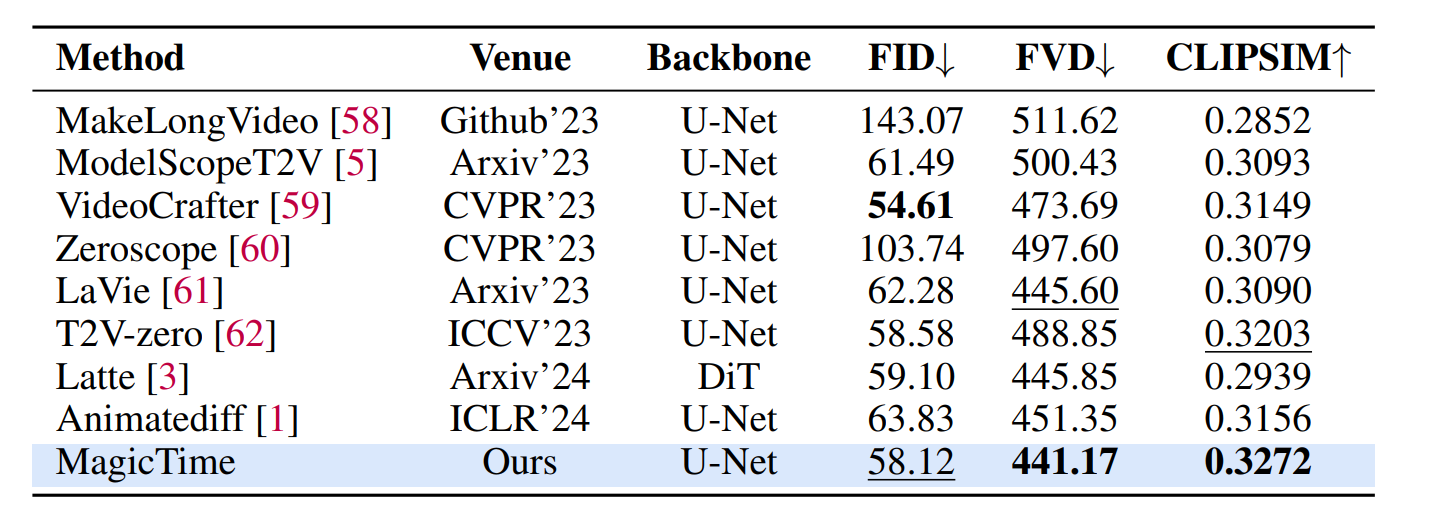
基于Diffusion1.5和Motion Module v15训练模型。 batch_size=1024,lr=0.4训练10k步,按照0.1比例空置text

5 Summary
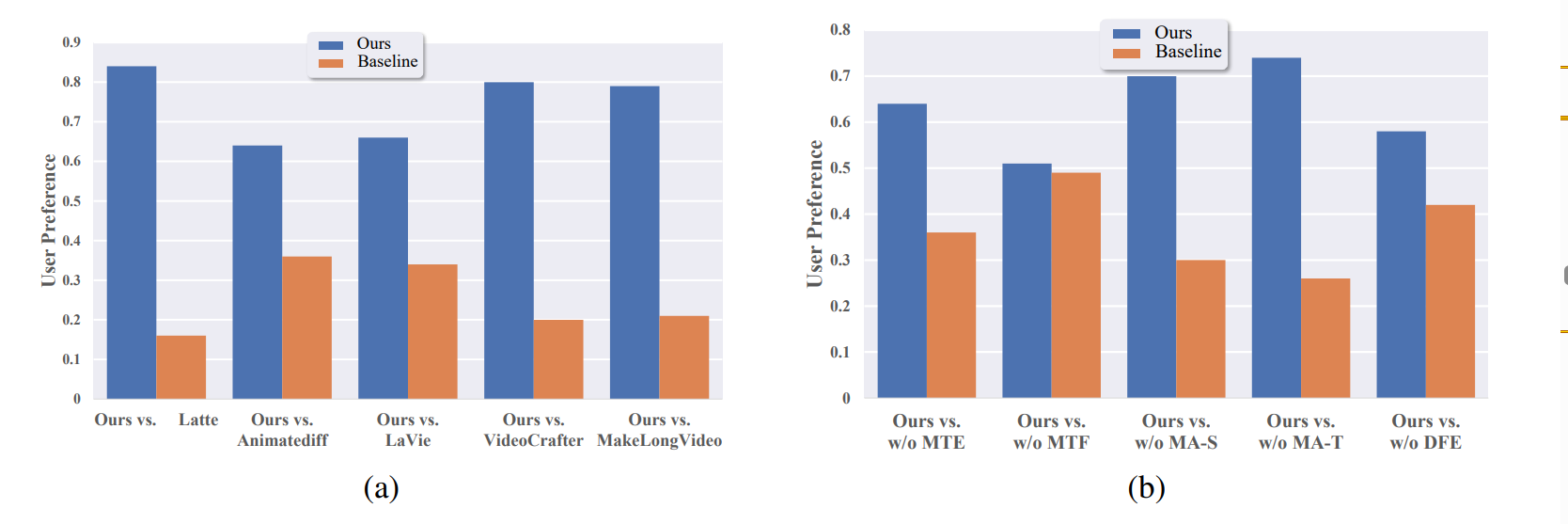
作者提出了现有视频生成模型在生成物理变化过程方面的视频的短板。 通过筛选切割和文本标注的方法,构建了一个针对物理变化过程的视频数据集。 然后用lora分别对图片处理部分的空间时间层,和文本编码器进行微调,提高了模型对物理过程的理解能力,生成出更符合物理世界规律的视频。 通过对比实验,消融实验,用户测试来证明了方法的有效性。 除此之外,还尝试结合了open-sora的SDDIT工作。
6 Comments
- 在讲MagicTime方法的时候突然提到了watermark,感觉起来很奇怪。 实验部分也没有展示生成的带有watermark的视频是怎么样的。 也没有展示关于watermark生成改善的任何直接证据。
- 视频数据里面的时间流逝和fps和其他的关于时间理解的问题在temporal consistency里面很关键,但是这个工作关注的稍微窄了些。 这个方面应该还有很多可以研究的地方。
- 总的来说这个数据集构造的非常出色,别出心裁,很有创新性。
metamorphic: 变质