Make-Your-Video
1 Introduction
1.1 Motivation
现在的T2V模型缺乏精确的上下文的控制能力。
他们选择通过深度图来表示动作结构,引导视频生成模型。
1.2 Key Design
- 分离时间模块和空间模块的训练,降低训练开销,利用图片数据进行预训练。 MagicTime,VideoCrafter,Stable Video Diffusion都有类似的设计。
- 加入textual和structural的特征引导,在T2V任务上得到了很好的效果。
- 用预训练image LDM做视频生成,充分利用预训练模型的视觉概念先验,并且得到时间一致性。
- temporal masking mechanism来支持长视频生成,缓解长视频生成过程中质量下降的问题。
2 Related Work
2.1 T2V & I2V
2.2 Text-driven Video Editing
原有在独立的视频帧上进行编辑的工作可能会导致时序一致性问题。 现有的视频编辑工作要么用预训练的视频生成模型,要么用预训练的T2I做inversion来进行编辑。前者由于高昂训练成本难以复现,后者需要复杂提示工程和手动调参。 和他们不同的地方在于,这个工作不依赖原视频作为视频编辑的输入。
3 Method
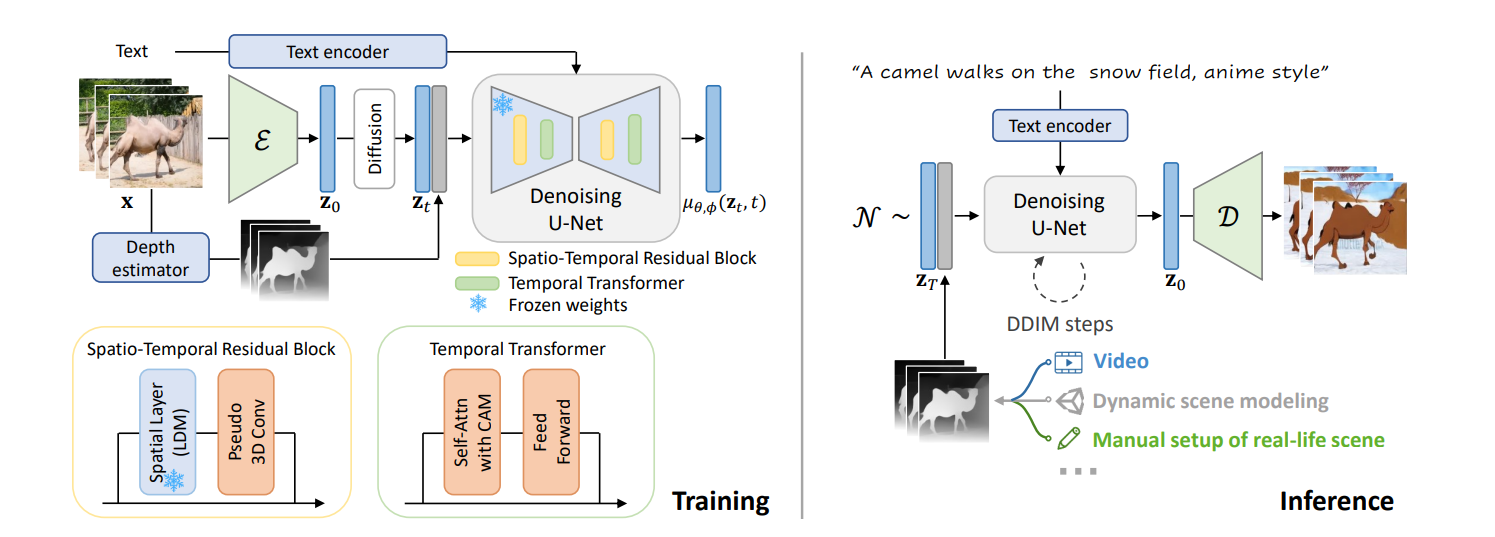
3.1 Latent Diffusion Model
方法部分照例还是一个LDM起手,这里就不再赘述,并且偷懒使用模版了。
扩散模型通常由两个过程组成:前向扩散和逆向去噪。 给定输入信号
其中
其中
其中
3.2 Adapting LDMs for Conditional T2V Generation
用一个深度估计预训练模型对每个独立帧都计算一个深度图,然后把深度图特征加到扩散之后的
这个操作类似DynamicCrafter的rich context representation
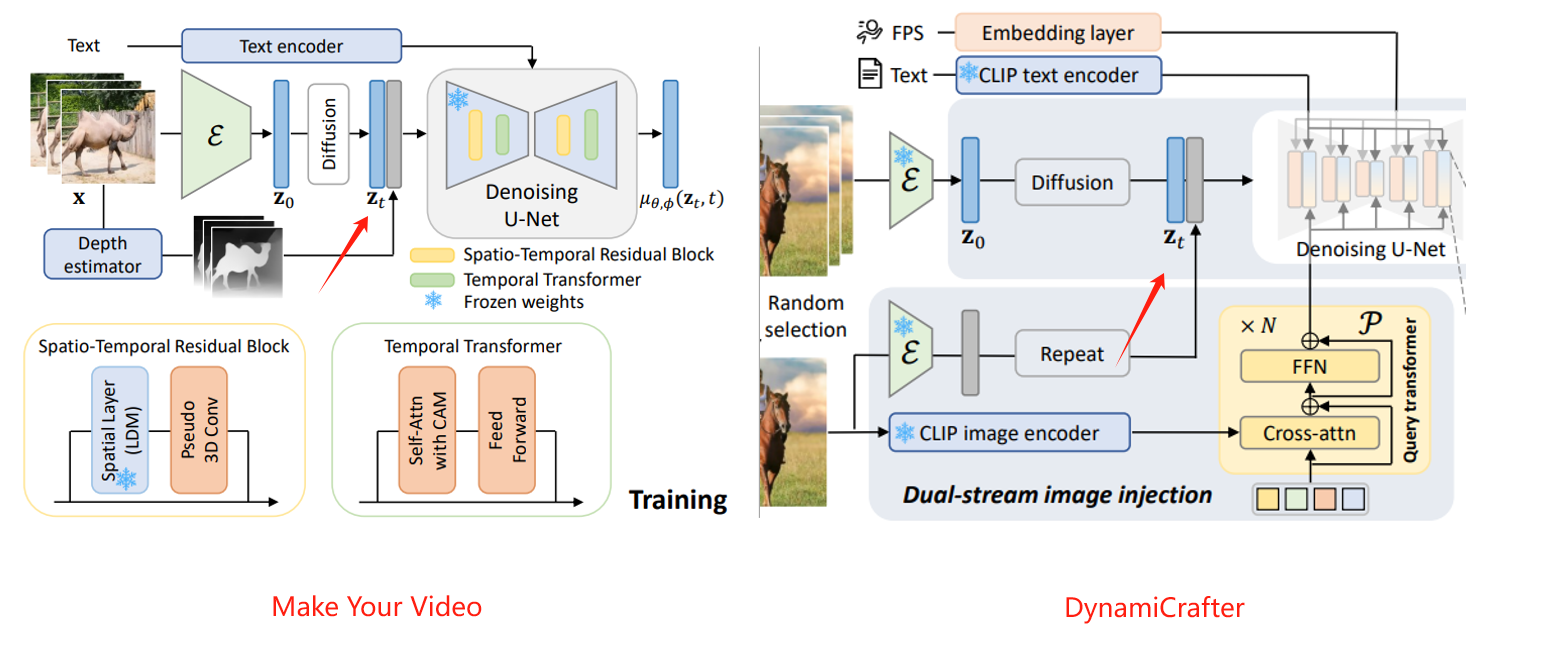
然后他们分别实现了一个时空残差块(spatio-temporal residual block)和一个(temporal transformer with CAM)到去噪的Unet 里面。
3.3 Temporal Masking for Longer Video Synthesis
作者认为一个可能导致长视频生成质量下降的原因是: 模型过拟合了固定数量的token,导致视频长度不能延长。 用causal attention mask (CAM)策略来让模型理解到token的长度。
4 Experiment
暂时跳过了
5 Summary
作者利用预训练模型加入深度信息来提升模型的空间感知能力,提高视频生成的动作质量。 利用一个CAM机制和随机时序掩码来提升模型的生成长视频的能力。 作者提出,模型可能在固定的token长度上过拟合,导致生成视频的效果变差事一个不错的想法。
6 Comments
- motivation还是有点不清晰 但是方法很明确