Stable Video Diffusion
curated:策划
tractable: 温驯
1 Introduction
Stability AI出品
他们将video dfiffusion分为三阶段训练:
- 文生图预训练
- 视频预训练
- 高质量视频微调
这篇文章包括:
- 展示一个精心设计的高质量数据集在训练中的重要性;数据预处理流程
- 微调模型策略以及微调结果
- 例如利用LORA的下游任务微调: camera motion specific
- 本模型包括3D先验,可以作为multiview diffusion的base
2 Related Work
2.1 Dataset Curation
在text-to-image和image modeling领域数据的筛选成为了是提高模型质量的重要策略,但是很少有在VideoGeneration里面被考虑。
WebVid-10M没有区分视频和图片数据,这样解耦图片数据和视频数据在最终模型中的影响比较困难。
3 Method
3.1 Data Processing and Annotation
https://github.com/Breakthrough/PySceneDetect Dectection Pipeline for clip cut detection.
利用image-caption对中间帧进行标注,用V-BLIP对视频进行标注,最后用大语言模型总结前两段标注。
3.1.1 cascaded cutting
- FFMPEG 大致cut
- pyscenedet 进一步cut
- RAFT : dense optical flow最后一步cut
character recongnition筛选出包含大量文字的视频。
最后用CLIP计算第一,中间和最后帧的embedding用来计算aesthetics scores和图片文本相似度。
关于dense optical flow和aesthetics scores的计算方法会更新在Diffusion Models
3.2 Image Pretraining
用SD2.1做backbone,进行图片预训练。
3.3 Curating a Video Pretraining Dataset
在视频数据上没有现成的过滤器,所以依靠人类偏好来过滤数据集,考虑人类偏好排序。
在CLIP,aesthetic, OCR, synthetic captions, optical flow scores等指标的辅助下,先随机选取10M的LVD的子集,然后依次删除到12.5,25,50%的最低质量数据。 对生成的描述词(synthetic captions)我们用ELO ranking。
然后在这些指标下,分别训练模型,可以找到每个指标对模型的影响程度。
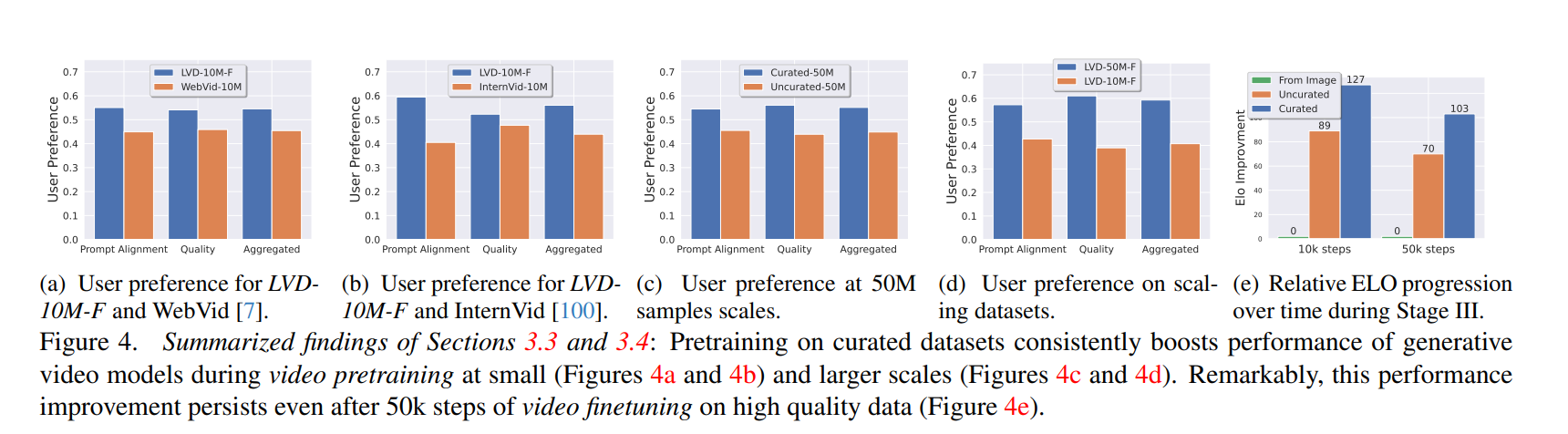
数据的筛选对模型训练效果的提升
接下来扩大数据规模,从10M到50M,效果证明Data Curation有利于模型规模的扩大。
3.4 High Quality Finetuning
对比了使用和不使用视频训练模型,10M和50M数据上训练的模型,得到结论:
- 分离video pretraining和video finetuning是有帮助的
- video pretraining对更大的数据集更有帮助。
4 Experiment
4.1 Human Preference Study
Appendix E的内容
让人们在视频的质量和文本一致性上进行评价
4.2 Applications
Camera Motion Lora
在小数据集上用LORA微调可以让模型生成一个图片相机进行水平,放大和静止的移动。
Frame Interpolation
让模型通过前后两帧预测中间三帧,10K步就够训练了。
Summary
先构造一个数据集,自动化的裁剪出更加合理的clip;
计算不同的评价指标,clip,aesthetic, optical flow etc;
先在一个子集上,用不同指标筛选数据,再训练模型,对比效果,得到不同指标对模型的影响;
接下来扩大数据规模,从10M到50M,以下是原文:
we repeat the experiment above and train a video diffusion model on a filtered subset with 50M examples and a non-curated one of the same size.
下游任务上可以使用小数据集进行微调
Comments
3.2节的实验真的豪横且严谨