T2V-Turbo
T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback
1 Introduction
1.1 Problem Statement
基于扩散模型的文生视频模型的采样速度很差。 所以想用consitency distillation的方法来提高采样速度。 与此同时还能提高模型的能力。
1.2 Stated Contribution
- 加速了 4-8 步
- 提高效果了
2 Related Work
2.1 Diffusion-based T2V models
文生视频, 主流方法还是基于diffusion.
2.2 DM inference accleration
- ODE/DPM solvers
- Consistency Models
2.3 Vision-and-language Reward Models
- open-source image-text RMs : HPS / ImageReward/ PickScore
2.4 Learning from Human/AI feedback
Reward Models给RLHF/RLAIF提供了支持。
本工作结合了 image-text RM和 video-text RM 训练了T2V-turbo
3 Method
3.1 Preliminaries
这里采用的一个连续时间步的常微分方程,也就是一个概率流模型来做扩散。
3.1.2 Consistency Models
根据PF-ODE的轨迹直接学习从x_t到x_0的映射。 定义consistency function满足:
即 任意时刻的 这个函数输出都一致。 这里的x_t和x_t'都来自同一个PF-ODE。

3.2 Reward Learning

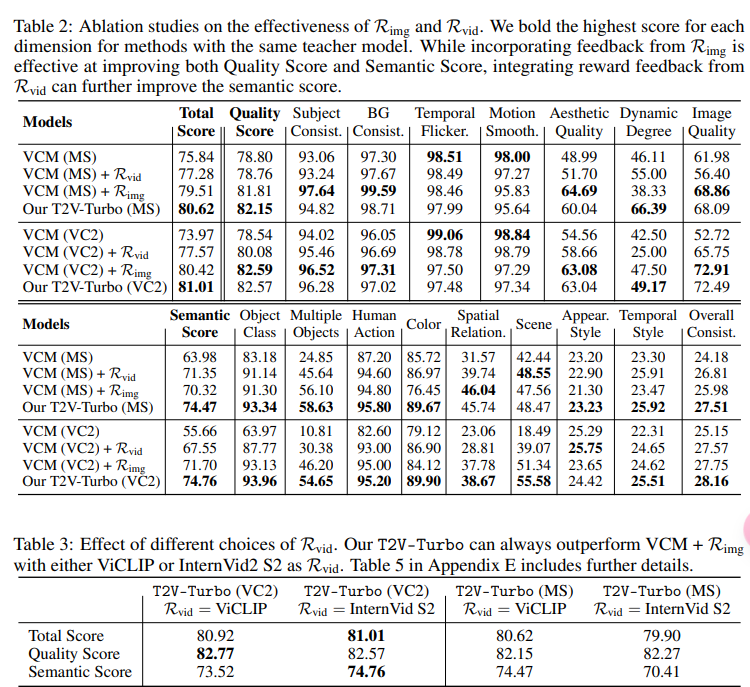
4 Experiment
4.2 Human Evaluation
这里用了一个amazon annotator