T2Vscore
1 Introduction
这篇文章来自NUS,NTU和TencentARC
1.1 Problem Statement
视频生成任务现在大火,但是FVD,IS, CLIP等指标不足以全面评价视频质量,导致了比较结果的不可靠。
之前我们已经精读过vbench和evalcrafter两篇文章。 三篇文章的思路都提到了对视频质量和文本视频对齐的分别评价,最终目标是将自动评价指标和人类偏好对齐。 通过构造一个测试数据集来全自动全面评价视频。
1.2 Stated Contribution
- 评价文图一致性和视频质量的指标
- TVGE Dataset
- 验证不同指标和人类偏好的一致性
2 Related Work
2.1 Text-to-Video Generation
PYoCo introduced the progressive noise prior model to preserve the temporal correlation and achieved better performance in finetuning the pre-trained text-to-image models to text-to-video generation. 这个论文加入阅读队列。
2.2 Evaluation Metrics
图片评价指标:PSNR,SSIM,MSE等
视频评价指标: 借鉴了图片评价指标对视频的每一帧进行评价,
视频质量测评: 一部分利用大型人类标注自然视频的数据集做训练,另一部分利用预训练的多模态模型
视频问答评价: 通过构造问题让问答系统(mPLUG)等做出评价
3 Proposed Metrics
3.1 Text Alignment
第一步: 解析文本,构建实体和实体之间的联系
将style和camera motion等作用在整个Prompt的词归为global element.
死去的离散数学开始攻击我,这个思路非常好,是前两个论文没有的。
但是实体关系构造的不好,会导致评价指标不行。
第二步: 构造问题和答案
用CoTracker提取视频的辅助轨迹,和视频一起输入到问答系统,然后通过问答系统的准确性来评价文本和视频的一致性。
3.2 Video Quality
在评价视频质量的时候有两个目标: 第一个是能够评价没有看过的视频,第二个是能够准确分析没有见过的模型。
3.2.1 Mix-of-Limited-Expert Structure
混合专家模型的结构。
- technical expert: 去检查视频的形变。 利用Fast-VQA做backbone
- semantic expert. 检查对物体的生成质量。 基于metaclip。
- 用ITUstandard混合两个质量
3.2.2 Progressive Optimization Strategy
逐渐减少可以训练的参数量。
- 端到端在LSVQ上训练, 28k videos
- 在MaxWell上小规模微调 FC layers 3.6 videos
- 在特殊的给定的形变上训练。
3.2.3 List-wise learning objectives
之前的工作指出,排序的偏序关系是更加可靠而且具有泛化性的。 所以这里用了rank_loss和linear loss结合的方法
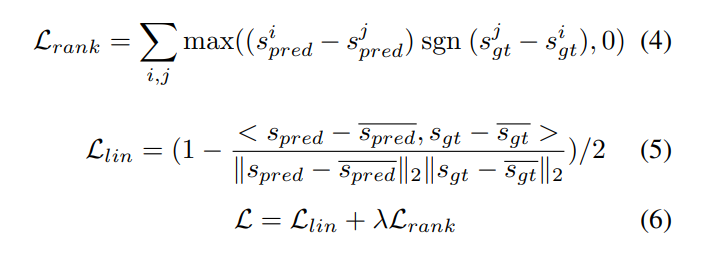
3.3 Dataset
本研究的一个不可或缺的部分是评估所提出的指标在文本条件下生成的视频上的可靠性和稳健性。为此,我们提出了文本到视频生成评估(TVGE)数据集,收集了有关T2V分数中研究的两个视角(对齐和质量)的丰富人类意见。对于这两个视角,TVGE都可以被视为首次尝试:首先,对于对齐的视角,该数据集将是第一个由大量人类受试者提供文本对齐分数的数据集;其次,对于质量的视角,虽然有很多关于自然内容的视觉问答数据库,但它们显示出与生成的视频显著不同的失真模式(在空间和时间上都是如此,参见图5),导致了一个不可忽视的领域差距。所提出的数据集将作为验证所提出的T2V分数与人类判断之间对齐的基础,此外,它还可以帮助我们的质量度量更好地适应文本条件生成的视频领域。数据集的细节如下:
视频收集。总共收集了2543个文本引导生成的视频,供TVGE数据集的人类评分。这些视频是由5个流行的文本到视频生成模型生成的,使用了EvalCrafter定义的多样化提示集,涵盖了各种情境。
主观研究。在TVGE数据集中,每个视频都由来自文本对齐和视频质量角度的10个经验丰富的人类受试者独立注释。在注释之前,我们对受试者进行了培训,并在TVGE的子集上测试了他们的注释可靠性。每个视频在每个视角上都以五点式评分,而每个分数的示例都在受试者的培训资料中提供。
分析和结论。在图6中,我们展示了TVGE数据集中人类注释的质量和对齐分数的分布情况。总体上,生成的视频在两个视角上都获得了低于平均水平的人类评分(µ对齐 = 2.59,µ质量 = 2.77),这表明需要不断改进这些方法,最终产生合理的视频。尽管如此,具体的模型也在一个单一维度上表现出良好的能力,例如Pika在视频质量上平均得分为3.45。在这两个视角之间,我们注意到一个非常低的相关性(0.223 Spearman's ρ,0.152 Kendall's ϕ),证明这两个维度是不同的,应该被独立考虑。我们在附录中展示了更多的定性示例。
4 Experiment
作者比较了不同的mllm,不同的传统指标和不同的辅助轨迹识别方法和人类评价的相关性。 和人类相关性强的方法被认为是更好的方法。 除此之外,在zero-shot和adapted的方法下的泛化性能。
5 Summary
这个文章通过预训练的VQA系统和多模态大模型完成了对视频评价指标的构建。 结构比前两篇文章简单。 前两篇文章的思路是类似的,这一篇有比较大的不同。