Vbench
1 Introduction
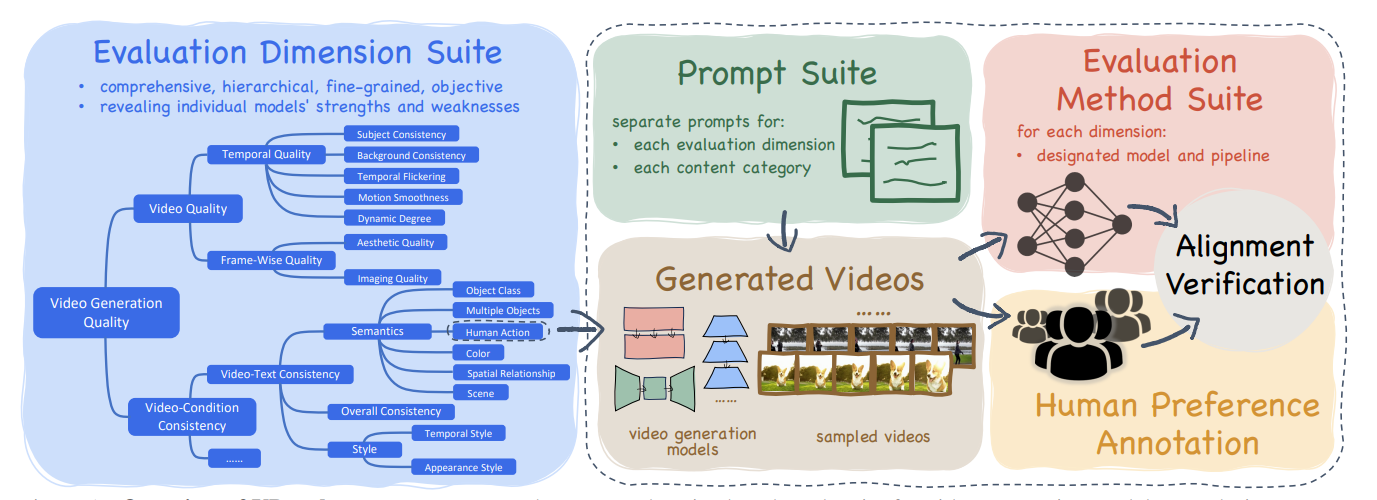
1.1 Problem Statement
为了全面评价视频生成模型,将视频质量解耦成不同的有明确定义的,互相不交叉的,能够量化的一组指标是必要的。 Benchmark对整理已有工作,启发未来工作具有非常重要的意义。
1.2 Motivation
已有的视频生成工作的缺点包括:
- 针对真实视频设计,不完全符合生成视频需要
- IS FID等指标和人类偏好并不一致
1.3 Stated Contribution
- 将视频质量分解为16个维度的指标
- 提供对人类偏好的对齐程度的评价
- 对未来工作的一些见解
2 Related Work
2.1 Video Generative Models
- 基于扩散模型
- text-to-video
- image-to-video
- video-to-video
- control maps :pose depth sketch
2.2 Evaluation of Visual Generative Models
- IS FID FVD CLIPSIM
- text-to-video的评价指标包括构成性(compositionality)和编辑能力等
- 现在的视频生成模型仍然缺乏和人类反馈对齐的全面评价指标
3 Evaluation System
整个评价系统是一个层次化的系统。 最上层是1)视频质量和2)视频条件一致性。
3.1 Video Quality
3.1.1 Temporal Quality
Subject Consistency
人,动物或者其他物体在视频中的连续性。
计算方法:帧间的DINO指标
Background Consistency
背景一致性
计算方法: 帧间CLIPSIM
这个idea合理,但是这么算是不是太粗糙了
Temporal Flickering
时间闪烁: 局部的高频细节的不真实
计算方法:帧间的差的绝对值的平均值
Motion Smoothness
- 看了补充材料才知道具体怎么算
Dynamic Degree
视频的动态程度: 是否包含大的动作
考虑拍摄一个静态物体,不做相机姿态变换,这个视频会接近对照片在时间轴上的复制,这就是一个动态程度很小的视频。
计算方法:RAFT
在时序一致性方面,可以理解静态一致性和动态一致性。 静态一致性: 考虑一个相机固定视角的视频,其背景大部分应该是几乎不动的。 动态一致性: 符合物理世界移动规律的运动。
3.1.2 Frame-Wise Quality
将视频拆分为图片的集合,然后对图片质量进行评价
Aesthetic Quality
人类眼中的视频帧质量评价
计算方法: 用LAION aesthetic preditor评价每一帧的美术质量。
Imaging Quality
评价图片的畸变程度:是否有过度曝光,噪音,等
计算方法: 用MUSIQ image quality predictor 测试
3.2 Video-Condition Consistency
视频和给定条件之间的一致性。
主要分为语义和风格一致性。 语义主要是对物体及其属性的描述。 这种符合程度是比较大尺度上的,例如是否有出现要求的猫,狗,车等等。 风格主要是整个图片尺度上整体特征,例如梵高的油画风格。
3.2.1 Semantics
Object Class
检测文本中出现物品提示词是否出现在图片中
计算方法: GRIT
Multiple Objects
检测视频生成模型同时生成多物体的能力
计算方法: 生成的正确物体占总的提示词中的物体的比例
Human Action
检测人的动作
计算方法:UMT
Color
物体的颜色是否符合提示词
计算犯法: GRIT
Spatial Relationship
物体之间的空间关系
计算方法:定义四种空间关系然后做基于规则的测试
Scene
生成的场景是否和提示词一致
计算方法: Tag2Text对生成的场景进行描述,然后检查和文本的相似度
3.2.2 Style
Appearance Style
风格举例:
“oil painting style”, “black and white style”, “watercolor painting style”, cyberpunk style”, “black and white” (油画,黑白,水彩,赛博朋克)
计算方法: 文图CLIP相似性
Temporal Style
时序风格: 是否有相机移动等
计算方法: ViCLIP
Overall Consistency
我们进一步使用ViCLIP(视频文本一致性计算工具) 对通用文本提示的整体视频文本一致性作为辅助度量标准,以反映语义和风格的一致性。
3.3 Prompt Suite
为了降低生成视频的开销,需要对测试的prompt集合进行精准的筛选。 对于每一个指标,都构造了100条测试。
然后构造了800个多标签的提示词,八个大类Animal, Architecture, Food, Human, Lifestyle, Plant, Scenery, and Vehicles各100个,测试视频生成模型不同的类别上的生成能力。
3.4 Human Preference Annotation
为了证明上述指标和人类偏好一致,构造了一个人类标注的数据集。
考虑四个视频生成模型,对同一个提示词各生成一个视频。这四个视频两两配对可以得6队。 对每个提示词生成五次,那么N个提示词可以得到Nx5x6对视频。
人类标注者在标注的时候被要求只考虑一个特定方面的指标,例如风格或者运动连贯性。
VLM tuning
用标注数据微调了VideoChat展示出来效果的提升。
4 Experiment
4.1 Per-dimension Evaluation
为了得到每个指标的经验最大值和最小值,作者用构造好的提示词集合搜索WebVid10M里最相似的文字标注,然后计算top5相似提示词的CLIPSIM,接下来随机裁剪2s视频作为评价的输入,最后将最大作为经验最大值。 用高斯噪音视频的指标作为最小值。 用整个WebVid上的视频的均值作为均值。
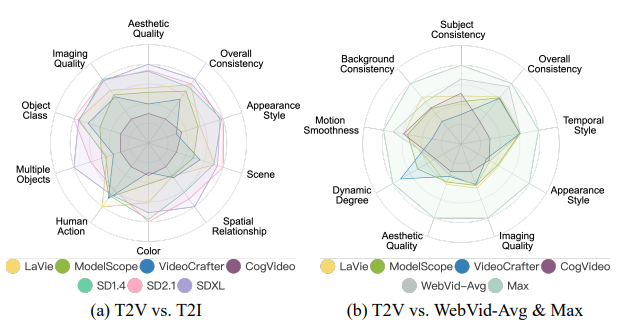
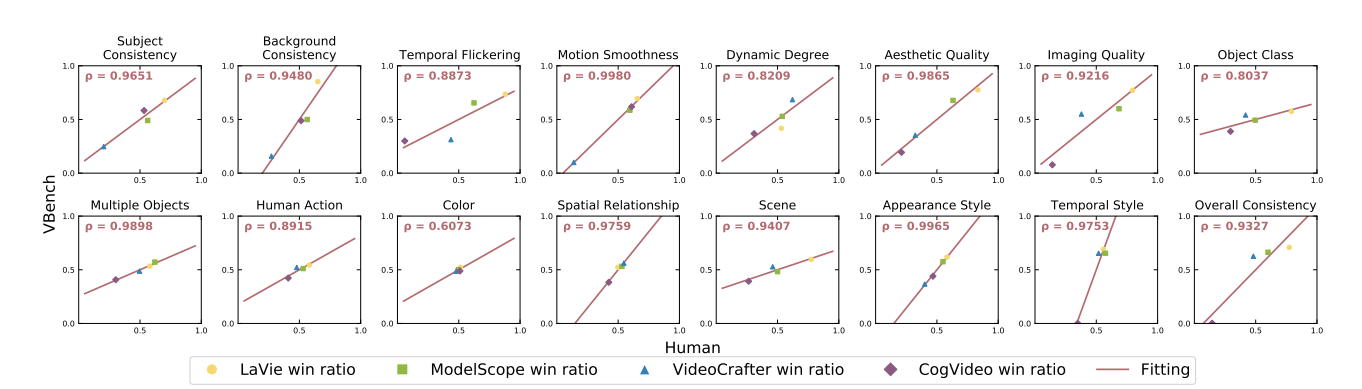
4.2 Validating Human Alignment of Vbench
计算人类标注和评价指标对两个视频好坏的判断的相关性。
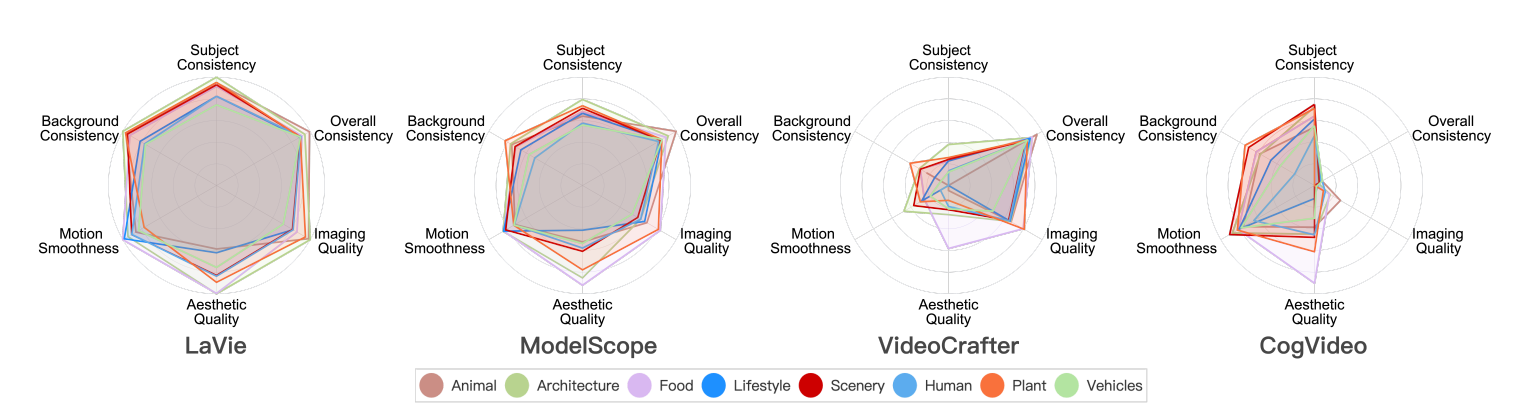
4.3 Category Evaluation
四个模型在八个类上的各个指标的评测效果。 VideoCrafter和CogVideo有点偏科,明显弱于前两个模型。
4.4 T2V vs T2I
文生视频模型和文生图模型的单帧评价指标比较结果展示:SDXL和SD2>SD1.4也基本大于视频生成模型。
5 Insights and Discussion
这一部分的主要观察和见解可以总结如下:
-
能力维度的权衡:
- 视频生成模型在时空一致性(主体一致性、背景一致性、时间闪烁、动作平滑度)和动态程度之间存在权衡。在时空一致性方面表现优秀的模型往往在动态程度上较低,因为这两个方面在一定程度上是互补的。例如,LaVie在背景一致性和时间闪烁方面表现出色,但动态程度较低,可能是因为生成相对静态的场景可以“作弊”以获得高时空一致性得分。相反,VideoCrafter具有较高的动态程度,但在所有时空一致性维度上表现不佳。这一趋势突显了模型在处理大运动动态内容时实现时空一致性的当前挑战。未来的研究应该同时关注这两个方面的增强,因为仅改善其中一个可能会影响另一个。
-
揭示特定内容类别中T2V模型的潜力:
- 分析表明,某些模型在不同内容类型上的能力差异显著。例如,在审美质量方面,CogVideo在食品类别表现良好,而在动物和车辆等其他类别中表现较差。各种提示的平均结果可能暗示了整体较低的“审美质量”(如图2所示),但CogVideo在至少食品类别中表现出相对强的美学能力。这表明通过定制的训练数据和策略,CogVideo可以通过提高其他内容类型的美学能力来与其他模型相匹配。因此,我们建议评估视频生成模型时不仅考虑能力维度,还要考虑具体的内容类别,以揭示它们的潜在潜力。
-
时空复杂类别中的瓶颈影响:
- 对于空间上复杂的类别(例如动物、生活方式、人类、车辆),模型在主要表现较差,尤其是在审美质量方面。这可能是因为在复杂元素中合成和谐的色彩方案、关节结构和吸引人的布局具有挑战性。另一方面,对于涉及复杂和强烈运动的类别(如人类和车辆),性能在所有维度上都相对较差,这表明动态复杂性和强度显著阻碍了合成过程,影响了空间和时间维度。这突显了在视频生成模型中改进动态运动处理的必要性。
-
处理复杂类别中数据量的挑战:
- WebVid-10M数据集将26%的内容分配给人类类别,是八个类别中最大的份额之一,但人类类别的结果却是八个类别中最差的之一。这表明仅仅增加数据量可能无法显著提高复杂类别(如人类)的性能。一种潜在的方法可能涉及集成人类相关的先验或控制,例如骨架,以更好地捕捉人类外观和动作的关节性质。
-
在大规模数据集中优先考虑数据质量:
- 在审美质量方面,图7显示食品类别几乎总是在所有类别中得分最高。这得到了WebVid-10M数据集的证实,根据VBench评估,食品在审美质量上排名最高,尽管仅占总数据的11%。这一观察结果表明,在百万级规模下,数据质量可能比数量更为重要。此外,VBench评估的维度可能对清理指定质量维度的数据集有潜在的用处。
-
构成性:T2I与T2V:
- 如图6(a)所示,T2V模型在多对象和空间关系方面表现明显不如T2I模型,这突显了增强构成性(即在同一帧中正确组合多个对象)的必要性。可能的解决方案包括:1)策划包含多个对象的训练数据,并提供明确描述这种构成性的相应标题;或者2)在视频合成过程中添加中间的空间控制模块或模态。此外,文本编码器的差异也可能解释了性能差距,因为T2I模型使用了更大或更复杂的文本编码器,相比之下,T2V模型可能使用较少或较简单的文本编码器,更具代表性的文本嵌入可能具有更准确的对象组合理解能力。
(LLM辅助结果)
- 如图6(a)所示,T2V模型在多对象和空间关系方面表现明显不如T2I模型,这突显了增强构成性(即在同一帧中正确组合多个对象)的必要性。可能的解决方案包括:1)策划包含多个对象的训练数据,并提供明确描述这种构成性的相应标题;或者2)在视频合成过程中添加中间的空间控制模块或模态。此外,文本编码器的差异也可能解释了性能差距,因为T2I模型使用了更大或更复杂的文本编码器,相比之下,T2V模型可能使用较少或较简单的文本编码器,更具代表性的文本嵌入可能具有更准确的对象组合理解能力。
6 Comments
- 跟EvalCrafter还是有些区别。 EvalCrafter先分析数据再有指标,这个指标是直接来的然后再证明。