VDT GENERAL-PURPOSE VIDEO DIFFUSION TRANSFORMERS VIA MASK MODELING
1 Introduction
1.1 Problem Statement
Video Generation.
他们的工作在做的时候是将Transformer加入Diffusion;但是这样做的动机不足
1.2 Stated Contribution
- 利用transformer的表达能力建模视频的时空特征
- 灵活的condition方法(concat in token space)
- 时空掩码的训练机制 可以让模型完成: 无条件生成; 视频预测; 视频插帧; 视频补全等任务
与同时期的Diffusion Transformer的工作相比: mask modeling 算是比较独特的一点。
2 Related Work
2.1 Image Diffusion Transformer
DiT and U-ViT
2.2 Video Generation Backbone
之前的主流都是用Unet做生成器的。 Transformer相对于Unet做生成器的好处有:
- Transformer可以同时实现视频生成,预测,补全等一系列视频相关任务
- Transformer的长序列建模能力可以捕捉时序信息
- Scalable and Model compacity
2.3 Mask Modeling
(论文没有,自己加的)
基于掩码的重建策略在语言建模、图像重建等任务中得到了广泛应用。通过去除部分输入信息,使模型在更困难的条件下学习到更本质的特征,从而提高模型性能。掩码语言建模:
掩码语言建模.掩码语言建模是通过将文本序列的一部分用掩码隐藏起来,让模型通过可见的上下文信息来重建被掩码的部分文本的方法。BERT利用双向Transformer Encode模型在掩码语言建模任务上进行预训练,在GLUE等指标上以更小的模型和训练开销取得了超越GPT1的效果。
掩码图片建模.掩码自编码器(MAE)将掩码重建策略扩展到图片重建领域。由于图片信息密度低于自然语言信息密度,掩码自编码器大幅提高掩码比例至75%,以训练出图片的核心表示。MAE在ImageNet任务上超越了BeiT和MocoV3,在图片分类、目标检测、语义分割等多个任务上都取得了SOTA效果。
多模态掩码重建.FLIP(Scaling Language-Image Pre-training via Masking)提出了在文本图片多模态模型中引入掩码进行预训练的方法。该方法通过最小化掩码后的文本和图片特征的对比损失来提高文本和图片特征空间的对齐程度。
LVDM里面也有类似的方法 Latent Video Diffusion
3 Method
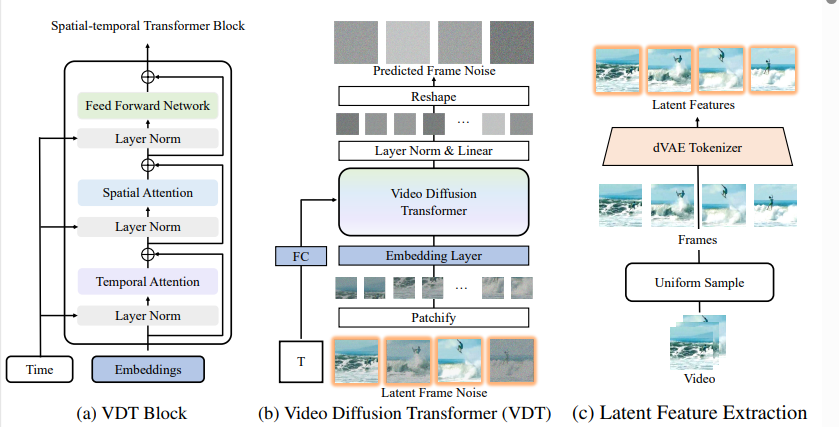
3.1 Transformer Block Design
模型的设计思路和Latte等工作还是非常类似的。 通过时序和空间两个方面的注意力机制来做视频建模和视频生成。
3.2 conditional generation
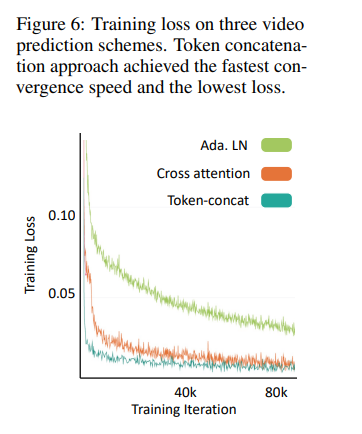
条件视频生成上用了三种方法:
- Adain Layer (我理解和Stylegan接近)
- Token Concat
- Cross Attention
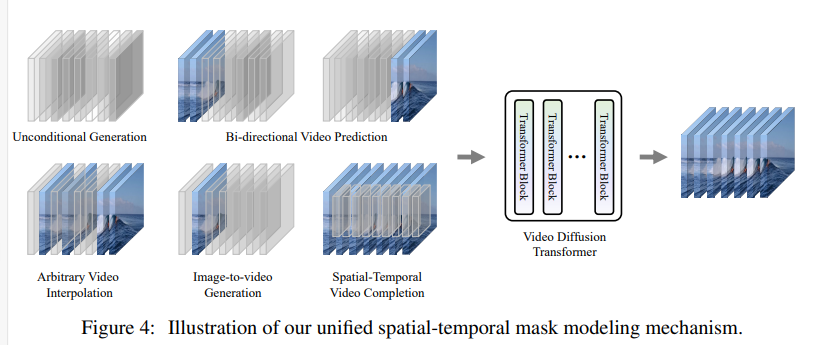
3.3 UNIFIED SPATIAL-TEMPORAL MASK MODELING
对视频帧进行掩码;
双向,单项,针对图片的掩码都有
4 Experiment
使用的数据集: UCF101; TaiChi ; Sky Time Lapse
都是公开数据集 相对来说不大 ; 实验规模和LVDM相近; 不如一些大规模的实验
Evaluation用了FVD, VQA , PSNR等等 ; 这篇工作早于各种backbone 只比这些也合理
5 Summary
提出了一个Video Diffusion Transformer的backbone
实验规模偏小,对一个声称要解决模型容量的backbone来说还挺严重的
但是做的挺早的,算是一次不错的尝试
这个工作的定位比较基础,相比于其他做具体application的工作来说可能会有更大后续工作的空间。 如果有后续的话,还挺希望看到关于更加详细的MVM(mask video modeling)的跟进的,比如到MAE那种程度的。