VideoCrafter
0 Introduction
Latent Video Diffusion之后的工作。
本文包含Text2Video和Image2Video两个Diffusion模型。
这是第一个开源的Image2Video的模型。
1 Method
这个工作包含text2video和text+image2video两个生成模型。 image2video模型通过加入image图片作为额外的条件输入扩散模型来生成视频。
1.1 Text2Video
1.1.1 video VAE
从SD继承了VAE用来压缩图片尺寸。 VAE将每一帧独立的压缩成latent
- 现在ClossalAI,PKU的opensora都还没有训练好Video VAE这个模块
1.1.2 3D denoising U-Net
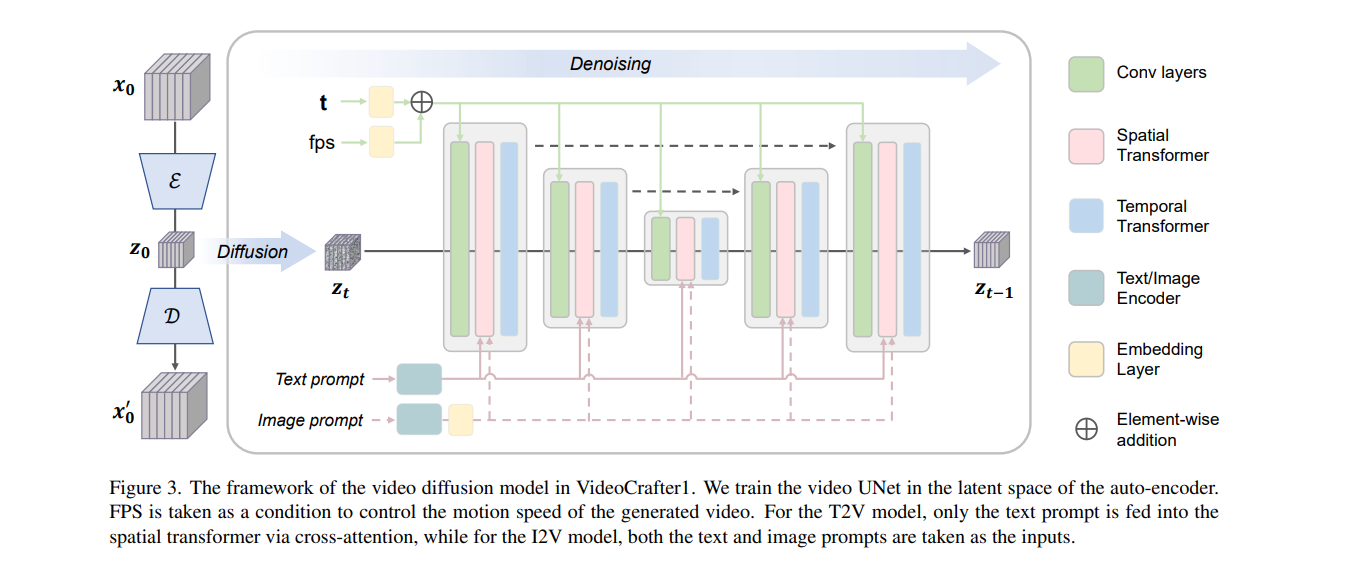
上图最左边是Video-VAE,通过Video-VAE得到的隐向量
一个Unet包含几个下采样和上采样层。 每层里面包含一个Spatial Transformer,一个Temporal Transformer分别处理空间和时间信息。 FPS和t作为条件添加到conv层中,文本和图片的编码特征通过交叉注意力机制放进Unet。
1.2 Image2Video
Text2Video Generation的过程中文本提供的信息对生成的视频中的物体非常重要。但是文本提示词只能提供semantic-level(语义级别)的信息,缺乏物体的细节信息。
Text+Image2Video可以给扩散模型提供更多具体的物体的信息。 不过这个过程要求图片信息和文本信息是对齐的,避免引导的过程中崩塌。
semantic-level在CLIP的论文里面有解释,即word-visual concept之间的对应关系,是粒度比较大的对齐。 在MAE里面有假设,图片模态在语义级别上的信息是稀疏的,因此可以进行高比例的mask.
1.2.1 Text-aligned Rich Image Embedding
CLIP Image Encoder的最后一维包含的语义信息(semantic information)丧失掉了部分细节。 所以这里采用CLIP Image ViT的最后一层特征作为conditional image information。 但是这层特征需要进一步和text embedding对齐,因此加入一个投影层P去学习对齐特征(对应图中Image Prompt右边的黄色方块)。
The text embedding
where
图片特征和文本特征通过一个 对称的交叉注意力层完成。
2 Experiments
2.1 Dataset
整个数据集包括
WebVid10M :20M 文本视频视频
LAION COCO :600M文本图片对
2.2 Training
采用和stable diffusionStable Video Diffusion一样的训练方法
- 256 batch size 上 训练 256
256的图片 80K 步 - 128 batch size 上 训练 512
320的图片 136K 步 - 64 batch size 上 训练 1024
576的图片 45K 步
2.3 Evaluation
Evaluation Method 来自 EvalCrafter: Benchmarking and evaluating large video generation models
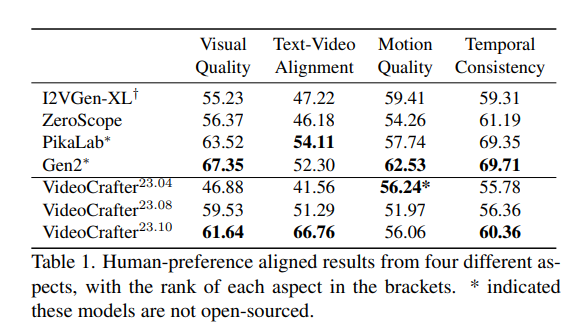
现有的开源模型只是一个起点。改进持续时间、分辨率和运动质量对于未来的发展仍然至关重要。
具体来说,目前这两个模型的持续时间仅限于 2 秒钟,将其延长到更长的持续时间会更有益处。这可以通过使用更多帧进行训练和开发帧插值模型来实现。至于分辨率,采用空间放大模块或与 ScaleCrafter [25] 合作是一种很有前景的策略。此外,利用更高质量的数据还能改善运动和视觉质量。
3 Comments
- very good step for video foundation model
4 implementation evaluation
4 prompt running on RTX 3090 using 368.86 seconds, about 10G memory of GPU
the efficiency is acceptable.
for videocrafter image2video v1, bs=10 can be supported at max.
VideoCrafter2
1 Introduction
他们在实验中观察到全参数训练会导致ST和TT有强耦合。然后他们在更高质量上的数据集诶条了这个模型,得到了更好的结果。
2 Related Work
AnimateDiff这个工作发现用WebVid10M训练出来的时序模块和LORA微调的SD结合在一起有图片质量更好的视频生成效果。 但是LORA不是一个一般的模型,使用性受限; LORA本身具有很强的个性化特征,可能会导致概念遗忘的问题。 为了解决这个问题,他们重新设计了训练Pipeline来解决ST和TT的耦合问题。
现有基于Diffusion的模型根据训练方法可以分为两类:
- full training. 用video数据在SD上全参数训练
- partial training. 只训练跟时序信息由关的部分。
3 Method
3.1 Parameter Perturbation 参数扰动
在同一个模型(VideoCrafter1)以相同的数据按照上面两种不同的训练方法进行训练。 VideoCrafter1用的是LAION-COCO 600M 和 WebVid-10M联合训练的。作者希望通过对指定模块的参数扰动来测试spatial module和temporal module之间的联系的强度。
扰动方法定义为:在数据集
3.1.1 对空间部分参数的扰动
对全参数训练的模型有:
PERTB
LORA解释参考Lora,Lora层负责在小数据集上学习一个参数层的低秩改变量。

空间参数扰动结果分析
- motion quality: 全量微调比部分微调更稳定。部分微调的结果随着微调步数边长变差的更快。微调到最后输出的video趋于静止,然后有闪烁。部分微调的结果退化了
- 部分微调的模型的visual quality更好; 全量微调的模型的picture quality和visual quality大幅度提升。 水印没了。
从这两点来看,全量微调的模型的时空连接更强,因为部分微调的模型的时空连接更加轻易的可以被破坏。 即部分微调的模型的motion quality(代表时序上的稳定性的指标)在微调的时候崩塌更快。
3.1.2 对时间部分参数的扰动
对时间参数的扰动公式如下,和空间扰动的类似:
对扰动的实验结果进行分析得出的结论是:
Full LORA Training 在Temporal特征上的训练可以得到更稳定的视频
Partial LORA Training在Spatial特征上的训练可以得到更好的图片质量
3.2 Data-level Disentanglement of Appearance and Motion
因为版权问题高质量的视频数据集不好获取,所以通过解耦训练的方法利用低清晰度的视频数据集WebVid-10M和高质量的图片数据集JDB等进行训练。
上面的参数扰动实验给我们设计训练流程提供了依据。
训练方法是: 全参数在视频数据集上训练,然后仅仅使用高质量数据集进行直接微调Spatical Module.
4 Summary of VideoCrafter1/2
VideoCrafter1 提出了一个模型架构,
VideoCrafter2针对VideoCrafter1里面的问题提出了训练方法。
5 Comments
从实验结果分析属性
Novelty. Parameter Perturbation 是一个非常有意思的方法,用来分析特征的稳定性。 这种方法应该在别的领域出现过,但是是第一次在神经网络上见到。
Demo Comments. 用VideoCrafter2在很多个prompt上生成了一个相对连续的电影,感觉这个领域很promsing。 如果可以延长prompt的长度从而获得提升就更好。
有了有了[fifo-diffusion]
除此之外,这个用lora扰动的方法给我们提示,当需要再新的数据集微调一个模型的时候,对模型效果的改变是可以有预期的。