Diffusion Models
Why Diffusion Success?
开门见山地我们来讨论一下Diffusion Models从理论到工程为什么如此的成功。
- 相比于之前的模型,统一了许多视觉的生成任务。 并且有延伸到判别分割检测任务的潜力。
- 模块化的实现让各个部分的改进可以解耦,训练-推理,加噪-去噪,压缩-重建,这些部分都可以单独的进行优化。
- 社区的支持,Stable-dffusion和Latent Diffusion开始,扩散模型的库变得非常的整洁。
TODO: Why Diffusion is not as successful as LLM?
0 高频概念
0.1 贝叶斯公式
0.2 KL散度
信息熵:
p是一个概率分布,x是p的取值(
我们可以把熵H理解成编码信息最小的比特数
KL散度:
考虑概率分布p,近似分布q
我们可以把KL散度理解为将p分布近似为q分布会有多少bit信息损失。
神经网络被认为是一个函数近似器(万能逼近定理) , 所以此处的q分布可以用一个包含参数
在Unconditional Diffusion会频繁用到这两个式子。
0.3 重参数化(reparameterization)
重参数化就是利用z表示X
1 Evaluation Metrics
1.1 IS Inception Score
清晰度,IS对于生成的图片x输入到Inception Net-V3中产生一个1000维的向量 y。其中每一维代表数据某类的概率。对于清晰的图片来说, y的某一维应该接近1,其余维接近0。即对于类别y来说,
多样性:对于所有的生成图片,应该均匀分布在所有的类别中。比如共生成10000张图片,对于1000类别,每一类应该生成10张图片。即
1.2 Fréchet Inception Distance
直接考虑生成数据和真实数据在feature层次的距离,不再额外的借助分类器。因此来衡量生成图片和真实图片的距离。
直观感受,**FID是反应生成图片和真实图片的距离,数据越小越好。**专业来说,FID是衡量两个多元正态分布的距离,其公式如下
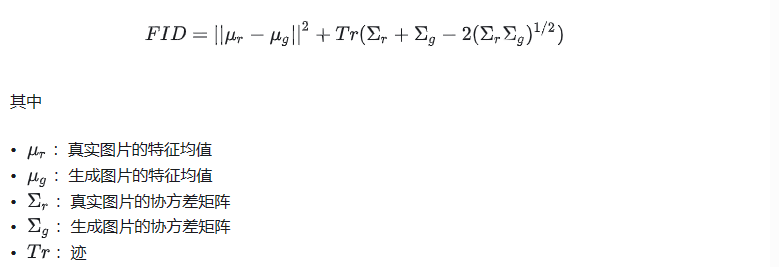
不同的实现会影响FID的计算结果,在各个论文之中汇报的结果可能来自不同的方法。
以下内容来自Tutorial on Diffusion Models for Imaging and Vision
2 AutoEncoders
AE(自编码器)有非常多的变体,这一类的方法都可以被视为是一种 压缩方法,负责把高维数据压缩到低维向量。
2.1 Variational Autoencoder(VAE)
VAE,变分自编码器, 利用概率分布来建模图片特征的方式。 对于生成类模型,个人认为理解概率分布是非常重要的一环。
相比于建模一个向量
我们的终极目标从
但是这个目标太难,我们考虑增加一个条件
但是我们在实现的时候并不是直接从X里面预测X的均值方差然后重参数化采样的,因为这样不能保证样本对应,从而难以训练。 要保证样本对应,实际的做法是对每个样本估计独立的专属的正态分布参数,然后各自采样,各自重建。
2.1.1 噪声的作用
直观上说噪音对生成的多样性有帮助,没有噪声就没有随机性,生成模型就不能生成。
2.1.2 变分的含义
VQ-VAE
https://github.com/AntixK/PyTorch-VAE/blob/master/models/vq_vae.py
为什么vqvae需要计算后验呢
Loss function
扩散模型的损失函数有一个非常严谨的推导,最后导出了一个simple loss.
除此之外,关于Unet输出结果是预测noise还是原始图片也有非常丰富的讨论,v-prediction etc.
[ need to be complished ]