Instruction Tuning Survey
Instruction Tuning for Large Language Models: A Survey
0 Abbreviation List
SFT: supervised tuning
IT: instruction tuning
RLHF: reinforcement learning from human feedback
DPO: direct preference optimization
LLM: large language model
1 Definition and Place
- Finetune Method of SFT [注意: IT也是SFT]
- 一般用在预训练之后
- 目标和动机: 弥补next-token-predicition和user objective两个优化目标之间的分歧。
- 这一系列工作最早是用在大模型,后来拓展到多模态领域。
- 从目标和动机来说: RLHF和IT是一样的。
- 现在大模型的训练流程: Pretrain-IT-RLHF
读了这个问题我们就不得不问: LLM 的 next token prediction是否真的有这么牛逼的功效-他的signal decomposition 是否真的和user preference 一致。
2 Current Exploration
2.1 Dataset Format
数据集由 {Instruction,output} 对构成。
IT和DPO都面临一个问题: 数据集构造的难度。 在预训练的阶段,数据的质量不如数据的规模重要。
2.2 Dataset Construction Pipeline
- 从传统的NLP任务的标注数据集里面用模版转换出数据对。 eg. Flan P3
- 手写少量的数据,然后甩大模型生成更多的数据。 eg. InstructWild , self-instruct
2.2.1 人工构造的数据集
手工构造的数据集在数据质量占有优势的同时,数据规模通常更小。
【因为我不做LLM IT,所以具体的IT数据集的一些构造方法就略写了】
文中列出的数据集有:
- natural instructions
- P3
- xP3
- Flan2021
- LIMA
- Super-Natural Instructions
- Dolly
- OpenAssistant Conversations
一个数据集的典型结构

2.2.2 蒸馏出的生成数据集
用预训练的大模型生成数据集通常更快,更有效。
蒸馏的方法一般从一个大的教师模型里面蒸馏出一个更加有效的小的学生模型。 这里面比较有标示性的工作是
- aplica: 52k GPT3 蒸馏的数据 在llama7b上超过了GPT3
- WizardLM: 逐渐增加query的难度得到更加丰富高质量的IT数据集
- Orca1-2:CoT的方式增强指令微调的效果。 可以超过GPT4.
- Baize:多轮对话 111.5k ChatGPT数据
除此之外,还有一些在特定任务上蒸馏特化的数据集:
- ShareGPT (现在有ShareGPT4Video)
- Vicuna(LLava的backbone)
- Unnatrual Instructions
2.2.3 self-improvment 的生成数据集
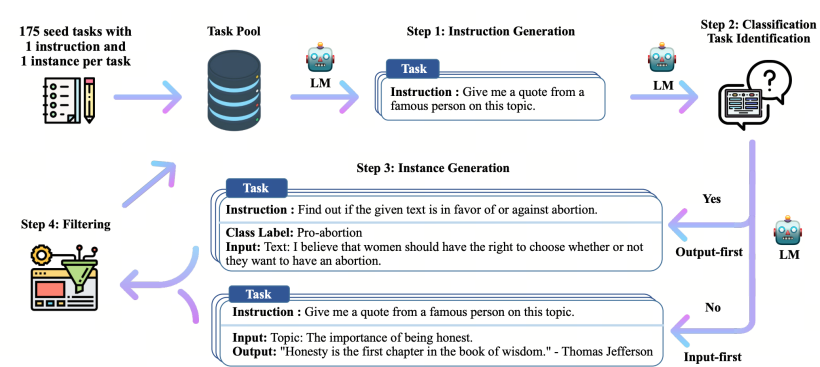
bootstrapping off its own generations:
问题的分类
这一部分对其他领域借用IT很有意义。
LLAVA定义了三类任务。

SPIN: Self-Play Fine-Tuning
Instruction Back-Translation
2.3 Multi-modality Instruction Fine-tuning
datasets
Models
2.4 Domain-Specific Instruction Finetuning
2.5 Efficiency Tuning
大模型高效微调手段分为
- adapter-based : HRA 参考这个论文的related work
- prompt-based :
代表性工作
- Lora:Lora
- Hint:
- QLora:optimal quantization and memory optimization
- LOMO: full finetune with low memory
- Delta-Tuning: optimal control perspectives for theoretical analyzation
2.6 Evaluation ,Analysis and Criticism
2.6.1 HELM evaluation
2.6.2 Low-resource IT
[Nuripes23]Instructdial: Improving zero and few-shot generalization in dialogue through instruction tuning:
25%的下游数据足够超越SOTA,6%足够平齐
2.6.3 Smaller Instruction Dataset
1000条高质量的数据足够
2.6.4 Evaluating Instruction-tuning dataset
IT的效果高度依赖IT数据集,但是IT数据集的质量评估却缺乏相关工作。
一些工作指出:
- 多个微调指令数据集结合起来可以提高模型能力
- IT对任何大小的数据集都是有帮助的