MAE
掩码自编码器
1 Introduction
本文提出了两个核心设计: 非对称的编码解码架构。 一个只编码可见部分,没有masked token的编码器,一个从隐向量重建原图的轻量解码器; 75%的掩码会生成不平凡有意义的掩码。
作者从自监督学习任务在NLP领域的成功开始思考,如何可以把masked autoencoders的思想引入计算机视觉任务。 他们提出思考:什么因素导致masked autoencoders在NLP和CV领域的不同:
- 架构问题. 在视觉领域卷积神经网络天然不适合加入诸如"mask token"和"position embedding" 这样的"indicators",但是ViT架构弥补了这样的缺陷。
- 信息密度. 图片的信息密度要低于自然语言的信息密度。
- 解码器角度. 图片解码器重建的是像素,文本解码器重建的是单词。 The decoder design plays a key role in determining the semantic level of the learned latent representations.
2 Related Work
- Masked Language Modeling. Bert:双向掩码 ; GPT: 单项掩码
- Autoencoding. 此处作者把PCA和k-means也认为是自编码机制。 并且把MAE归为一种新的DAE(Denoising autoencoders)
- Masked Image Encoding. ViT ; BEiT;
- Self-supervised learning. 自监督学习-对比学习
3 Method
- Masking. 跟ViT一样将图片划分为不重叠的块。 ViT用的是ConV的Stride实现这点。 随机从这些块里面选择一个子集,这个操作记为"random sampling". 大比例的random sampling可以极大降低计算复杂度。
- MAE Encoder. 只接受可见的部分作为输入,用线性投影和位置编码处理后,加入Transformer. 没有Mask Token。 这样可以训练更大的Encoder
- MAE Decoder. 输入编码后的visible patch和mask token. 给mask token加上了位置编码保证有位置信息。 MAE Decoder是独立于Encoder结构的,受下游任务决定。
- 重建目标. 预测pixel values. 损失函数是MSE。 类似BERT,只在masked patches计算loss. 做了关于损失函数的实验。
- 不需要稀疏操作,直接用列表移除固定比例的token.
4 Experiments
backbone: ViT large
对比了从头训练200和MAE的方法和微调的方法50轮
消融实验的数据都以800轮预训练为准,1600轮没有明显提升。
MocoV3训练300轮会有提升。 但是MAE每轮只看见25%的patch,但是MocoV3每轮会同时看到两次裁剪后的图片,甚至更多。 MAE训练1600轮的时间比MocoV3训练300轮低。
4.1 消融实验
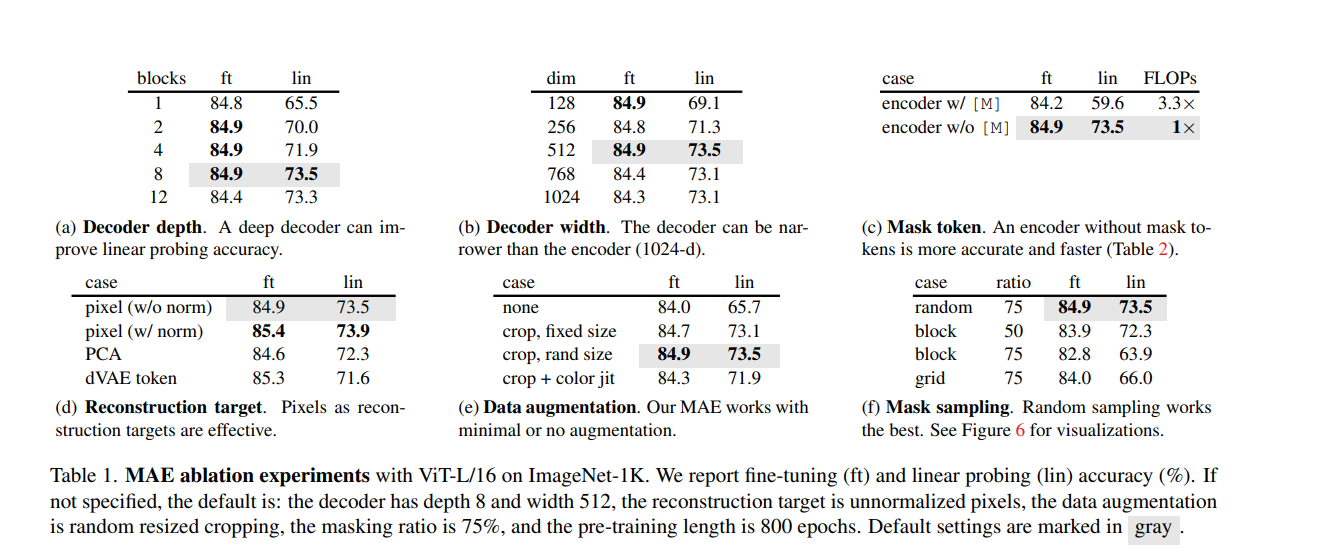
上表分别分析了在fine-tuning和linear-probing的条件下,解码器深度,宽度和Mask Token,预测结果,数据增强和掩码采样方式的消融实验。
这里看出在 8层 512d的decoder下,无mask token,随机采样mask,将重建损失设置为norm pixel values,用crop rand size有最好的结果。
4.1.1 微调范围
微调最后一个Transformer Block对最终效果有巨大提升。
微调最后半个Transformer Block对最终效果也有提升。
调整最后几层可以获得和全参数微调相同的效果。
MAE学习到特征是更非线性的,所以有一个非线性头被微调的时候效果更好。
4.1.2 下游任务
目标检测和目标分割.
pixel-based MAE比BEiT好,也比Moco-V3更好
语义分割. COCO数据集上提升了3.7个点
分类任务. 大幅提升
5 Discussion
Simple algorithms that scale well are the core of deep learning.
自监督学习在NLP里面已经非常常见,但是在CV里面监督学习仍然占据主导地位。 在ImageNet和迁移学习领域autoencoder是非常类似NLP技术的,具有可扩大性。
尽管在NLP里面的技术值得借鉴,但是自然语言和图片之间的天然差别需要被合理的处理。
6 Comments
Simple Effective 但是不太Cheap
从NLP的论文里面借鉴了一些想法,然后做出了针对图像数据的改进。
关注到了Scalable这个属性,神经网络的一些性质好像是之前我们思考的比较少的部分。
在实验中也给出了对于不同重建目标效果的对比,说明了norm pixel value, pixel value等重建目标带来的不同差异。
Mae中间有一节专门是 simple implementation。 Kaiming是从来不害怕 实现方法简单的。 Simple and work
这个工作也没有非常复杂的模型图 网络结构主要靠描述 虽然但是我们这种应该是学不来
另一个启示是: 学着分析实验结果,和设计实验。 Kaiming的实验是非常扎实的。
6.1 contribution
一种新的理解Encoder-Decoder架构的方法
新的理解representation ability的地方
Kaiming之前做了Moco几个对比学习的方法也是关注representation的
6.2 Summary
假设我需要引用这一篇文章,放进我的相关工作,我会怎么样描述这篇文章
MAE采用了非对称的自编码器结构,将图片重建任务的掩码比例提升到75%,在视觉预训练和检测分割分类等下游任务上得到了SOTA的结果。