Lora
agnostic:不可知的
1 Introduction
随着模型参数数量增大,全参数微调变得越来越不可能。 过去的工作表明仅训练模型的最后几层可以得到和全参数微调类似的效果。 也有工作探索插入小模块进行训练的工作。 Lora(low rank adaptation)提供了一种大幅度所有模型参数的训练方法。 Lora有以下几个贡献:
- 多个LoRA模块可以共用一个模型来完成不同的下游任务
- 减少需要训练的参数量,降低训练硬件门槛
- 无推理延迟
- 可以应用在不同的方法上
2 Related Work
2.1 Adapter Layers Introduce Inference Latency
在每个Transformer后面加入新的层进行微调会降低推理速度。 作者在GPT2上对比了Lora和增加Apapter Layer的方法带来的延时问题。 在训练的时候,batch_size较大时,时间延迟尚不明显,但是在推理条件下,单GPU和单样本推理的时候,时间延迟会非常大。
2.2 Directly Optimizing Prompt is Hard
直接做prefix tuning延长了prompt长度,下游任务可用的prompt就减少了。
2.3 Low rank structures in deep learning
在机器学习领域,低秩结构是非常常见的,很多机器学习方法都有低秩的性质。 在理论层面,我们已经知道神经网络超过其他经典方法有一部分原因就是低秩结构的存在。 但是我们还没有发现将低秩更新用到神经网络学习中的工作。
3 Method
考虑一个预训练的权重矩阵
BA是可学习的矩阵,A初始化为随机高斯分布,B初始化为0,所以BA一开始为0。 这个zero initialization的方法controlnet是不是也用到了。
这个方法是Full fine-tuning的一个变种。 因为训练过程中产生的梯度不再累计到预训练的权重矩阵
3.1 Applying Lora to Transformer
作者选择将Transformer里面的W_q,W_k,W_v进行微调,同时保持MLP层不动。这样做的好处是可以减少训练数量,降低VRAM开销,避免IO的瓶颈,带来更高的训练速度。 在GPT3上,避免将不优化的参数放进优化器可以减少70%的显存开销,进行r=4的低秩分解训练又大大降低了chekcpoint大小。
4 Experiment
作者在这个方法上进行了丰富的实验验证方法的有效性。
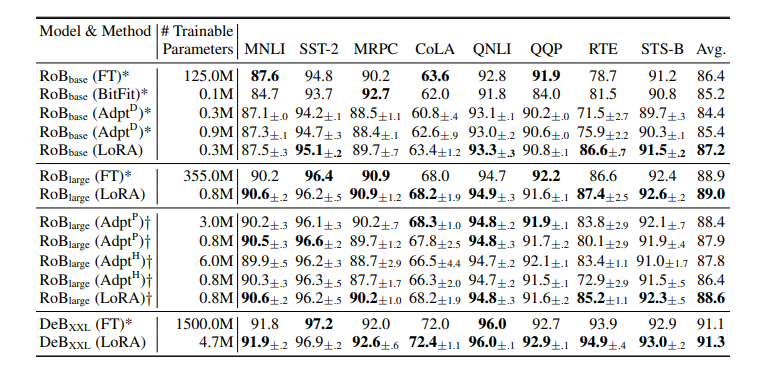
- FT是只微调预训练模型的最后两层
- BitFit是只训练Bias
- Prefix-embedding tuning是训练不在词表的token的嵌入向量,然后将这个token加入prompt来提高性能。
- Prefix-layer tuning. 除了训练嵌入向量,还训练Transformer的activation layers
- AdapterH:插入两个MLP; AdapterL:插入layernorm; AdapterP;AdapterD:扔掉部分微调层。
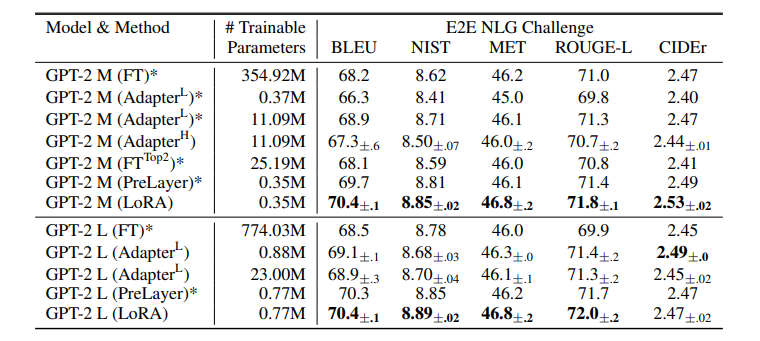
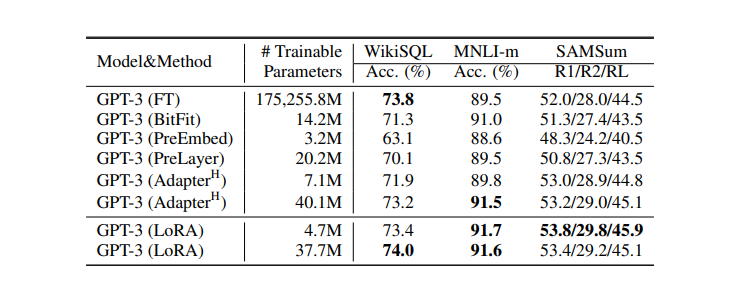
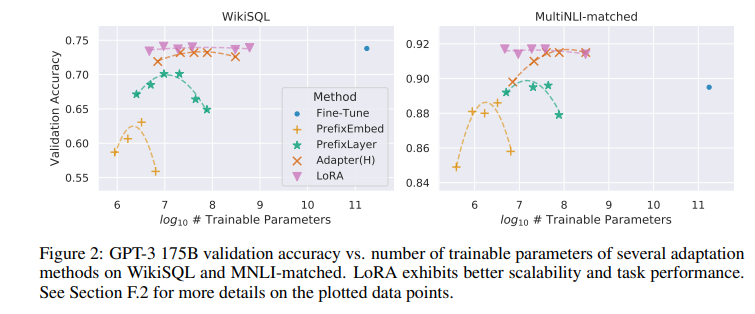
5 Understand Lora
5.1 哪个权重矩阵应该加Lora
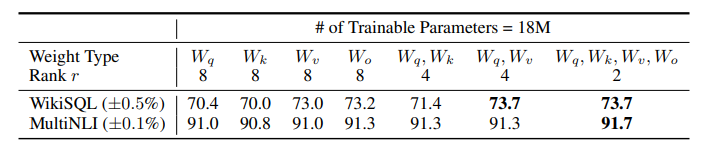
5.2 对于Lora来说 最好的r是多少
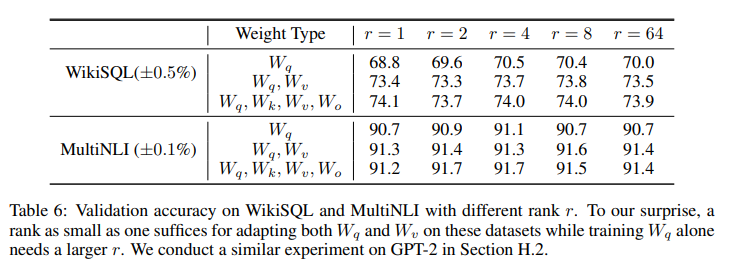
5.3 不同r下的子空间相似度
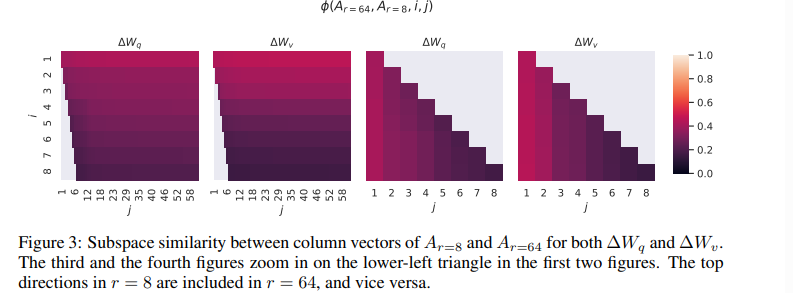
6 LoRA实现
在一个特定的条件下,我们通过pytorch lightning框架做训练的时候,是没有封装好的Lora的,所以需要我们自己实现。
需要对一个模型实现一个LoRA需要最少的关键模块是:
- 对原模型的查找函数,负责找到需要被替换为LoRALayer的层
- LoRALayer层本身,这个模型对于上下层来说应该是无感的,即他的行为应该和被替换的Linear或者Conv层一致。
- load; unload; save 函数