CLIP
1 Introduction
之前的计算机视觉的系统都是在给定任务上全监督的训练。 这种训练方法导致泛化性能受限, 所以一种替代方法是用更加普遍的文本来作为监督信号。
2020年的GPT3等工作证明了在互联网数据集上的大规模预训练的效果会比高质量的标注的数据集上训练效果更好。 而视觉任务上预训练模型依然是基于标注数据的(ImageNet)。 在之前的工作中用自然语言作为监督信号的图片表征学习的性能远远不如监督学习。 但是弱监督学习的预训练任务被证明是有效的。 弱监督学习和最近的基于自然语言的图片表征学习的关键差异是规模哦。
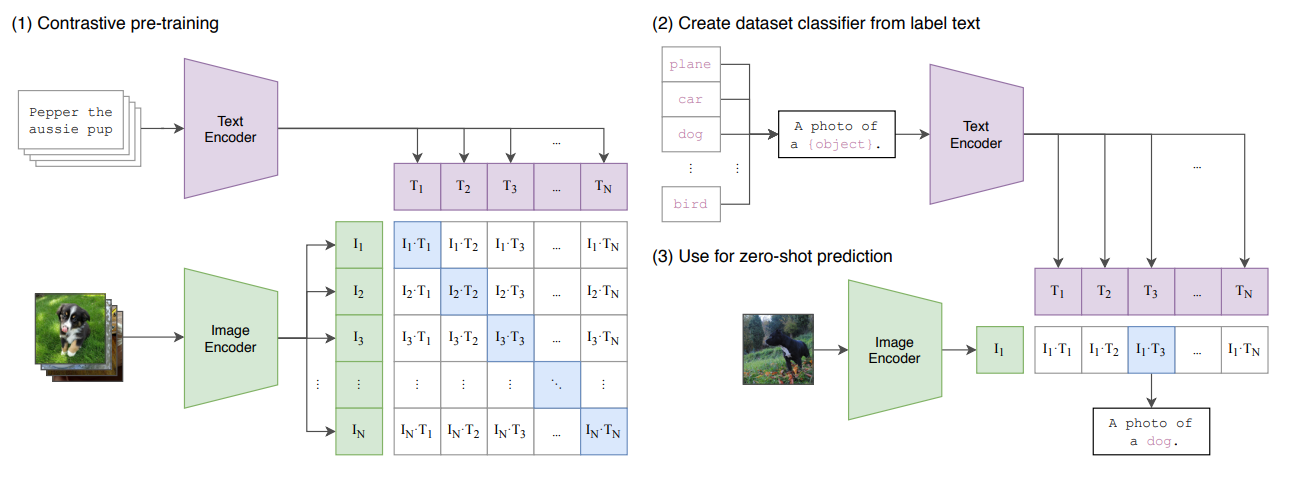
2 Approach
2.1 Natural Language Supervision
用自然语言作为监督信号不是一个新的想法,尽管过去的工作采用了例如n-gram之类的方法来简化表征自然语言。 用自然语言作为监督信号相比于其他的监督信号的好处是利用互联网上大量的数据学习到足够好的表征保证zero-shot的迁移能力。
2.2 Creating a Sufficiently Large Dataset
对MSCOCO,YFCC100M等数据集进行筛选,得到15M图片。但是这个数量仅仅和ImageNet相当,为了实现Motivation里面提到的利用自然语言数据进行足够的监督,还需要在网上找到更多的数据。 最后得到了400万对图片文本数据,超过50w个查询。 这个数据集的大小和GPT2的训练数据集类似。
2.3 Selecting an Efficient Pre-training Method
作者分析在ImageNet上做预训练的两个工作分别用了19个TPU年和33个TPU年的事实,提出训练效率是用自然语言进行监督的核心。
最开始用一个ImageCNN和text transformer一起训练,但是63M参数的text transformer降低了预测速度。 因为这些任务都想要找到精确的词来描述图片,但是对图片的描述有非常复杂的组合。
又受到对比学习任务的启发,他们探索了一种代理任务来进行预训练。 将文本描述作为一个整体和图片进行配对。 在一个N个图片文本对里,可以产生
因为数据集足够大,所以不太需要考虑过拟合的问题。 图片编码器没有用ImageNet预训练模型初始化,文本编码器同样没有初始化。 和其他对比学习任务一样,用了一个MLP来做分类头。 图片数据值用了随机裁剪做数据增强。
2.4 Choosing and Scaling a Model
图片编码器方面,作者首先选择ResNet-50做backbone,因为他在很多任务上都显示出了良好的泛化性能。 然后做了一下轻微的改进,例如加入注意力池化层。 然后用了2020年提出了ViT结构,除了加入一个额外了layer norm给patch和Position embedding之外,不做改变。
文本编码器方面,用了一个Transformer-base,63M参数,用BPE做tokenizer,49152的词汇带下。 seq_len裁剪到76。
在放大模型的时候,Resnet的宽度和深度和分辨率被同时放大了。 Text Transformer只放大了模型的快读。
2.5 Training
训练了一系列的5个 ResNets 和 3 个 Vision Transformers。对于 ResNets,训练了一个 ResNet-50,一个 ResNet-101,然后还训练了 3 个按照 EfficientNet 风格模型缩放的版本,分别使用了大约 ResNet-50 计算量的 4 倍、16 倍和 64 倍。它们分别标记为 RN50x4、RN50x16 和 RN50x64。
对于 Vision Transformers,训练了一个 ViT-B/32,一个 ViT-B/16 和一个 ViT-L/14。所有模型都训练了 32 个 epochs。
使用了 Adam 优化器(Kingma & Ba, 2014),应用了分离的权重衰减正则化(Loshchilov & Hutter, 2017)到除增益或偏置外的所有权重,并使用余弦学习率调度(Loshchilov & Hutter, 2016)来衰减学习率。
初始超参数是在基准 ResNet-50 模型上通过网格搜索、随机搜索和手动调整 1 个 epoch 的训练结果进行设置的。由于计算限制,超参数随后被启发式地调整以适应更大的模型。
可学习的温度参数 τ 初始化为等同于 (Wu et al., 2018) 中的 0.07,并进行了截断以防止对数值过大导致训练不稳定。
使用了非常大的 minibatch 大小为 32,768。采用了混合精度训练(Micikevicius et al., 2017)以加速训练并节省内存。
为了进一步节省内存,使用了梯度检查点技术(Griewank & Walther, 2000; Chen et al., 2016)、半精度 Adam 统计量(Dhariwal et al., 2020)和半精度随机舍入的文本编码器权重。
嵌入相似性的计算也进行了分片处理,每个 GPU 只计算其本地嵌入批次所需的配对相似性子集。
最大的 ResNet 模型 RN50x64 在 592 个 V100 GPU 上训练了 18 天,而最大的 Vision Transformer 在 256 个 V100 GPU 上训练了 12 天。
对于 ViT-L/14,还在更高的 336 像素分辨率上额外预训练了一个 epoch 以提高性能,类似于 FixRes(Touvron et al., 2019)。我们将这个模型标记为 ViT-L/14@336px。
3 Experiment
3.1 Zero-Shot Transfer
3.1.1 Motivation
zero-shot learning起初是指在图片分类任务中泛化到没有见过的物体的。 CLIP中将这个概念拓展到没有训练的数据集。 CLIP可以被看做是通过代理任务来提升在未见任务上能力的方法。 作者这将zero-shot transfer作为一种评价机器学习系统进行任务学习的方式。 而一个数据集评价了一个机器学习系统在一个任务的特定分布上的能力。 所以这种zero-shot的能力是对CLIP的对分布偏移的鲁棒性和领域泛化能力的评价。
Visual N-Grams是第一个研究zero-shot transfer在图片分类任务上的方法,也是唯一一个认识到研究了到图片分类任务的迁移学习的工作。 他们的方法构建了142806个visual n-gram,然后最大化给定图片的n-gram 文本的概率
NLP的GPT1 GPT2也是通过迁移学习的方法,不用任何有监督的学习来提升特定任务上能力的工作,给CLIP了另一条参考。
3.2.2 Using CLIP for Zero-shot Transfer
首先将预先定义好的label构造成text prompt,然后编码得到一组label的特征。 对于每一张输入的图片,计算其特征,然后和label计算余弦相似度。 将余弦相似度最大的label作为分类结果。
3.2.3 Initial Comparison To Visual N-Grams
CLIP在ImageNet上的top1 top5准确率能够和完全监督的方法进行比较,在无监督的视觉任务上取得非常大的进展。
在小数据集上从头开始训练小CLIP系统,以一个相对公平的资源消耗比较了在几个数据集上结果,都大幅提升了预测准确率。
3.2.4 Prompt Engineering
在传统的图片分类任务中,label通常被抽象成id 整数给模型的,然后再通过一个额外的映射得到文本label.
CLIP的研究发现,在文本图片配对的数据集中,单个单词的标注是非常稀少的,而且单个单词的标注会引起歧义。 所以提出了利用prompt engieering的方式来提升在不同数据集上的表现,例如将label改成a photo of label; 在卫星数据集集上,可以用a satellite photo of label ; 或者指明物体类别: a photo of label , a type of pet.
3.2.5 Analysis of Zero-shot Performance
作者在20+个数据集上比较了Resnet50监督训练的效果和CLIP的zero-shot效果。 有16/27个数据集上效果表现得更好,在一些复杂的特定领域的数据集上(卫星图片分类,肿瘤图片分裂,交通信号分类)仍然存在困难。然而非专家的人类可以在这些数据集上表现的很好,说明CLIP仍然有进步的空间。
然后作者进行了few-shot效果和zero-shot效果的对比。 作者测试了不同的预训练模型每个label不同的标记数量的效果,发现zero-shot CLIP基本能够达到16个instance做few-shot的效果。 除此之外,few-shot的CLIP在4-shot以上的时候超越了zero-shot的效果。
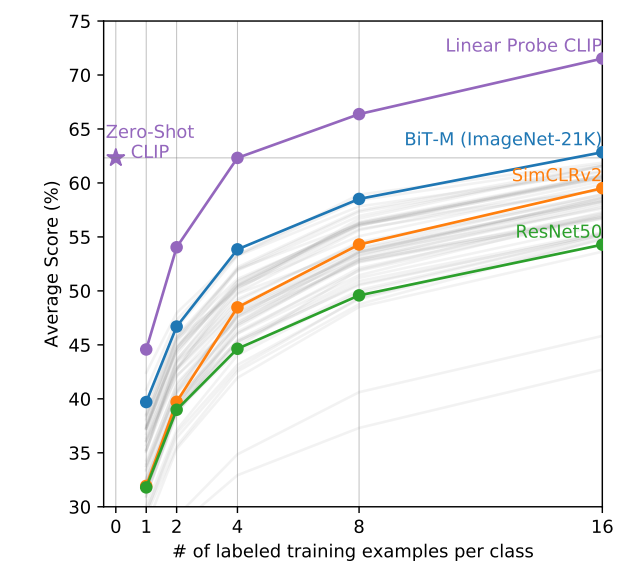
在这些比较中,零样本性能与完全监督性能之间存在着显著的正相关性(相关系数为 0.82,p 值小于 10^-6),这表明 CLIP 在连接底层表示和任务学习到零样本迁移方面相对一致。然而,零样本 CLIP 只在 5 个数据集上接近完全监督性能:STL10、CIFAR10、Food101、OxfordPets 和 Caltech101。在这 5 个数据集上,零样本准确率和完全监督准确率均超过 90%。这表明 CLIP 在底层表示质量较高的任务中可能更有效地进行零样本迁移。
作者还通过线性回归模型预测零样本性能与完全监督性能之间的关系,发现每提高 1% 的完全监督性能,零样本性能提高约 1.28%。然而,95% 的置信区间仍然包含小于 1 的值(0.93-1.79),表明这个关系可能存在一定的变化。
3.2 Representation Learning
上一节可以被认为是task-learning,但是representation learning也是评估模型的重要方面。 常见的评价方式是在预训练模型上加一个线性层做分类,另一种是用端到端的微调。 这里选用了线性层, 为了避免微调对预训练表征的修改,更加真实的展示CLIP预训练的表征的性能。
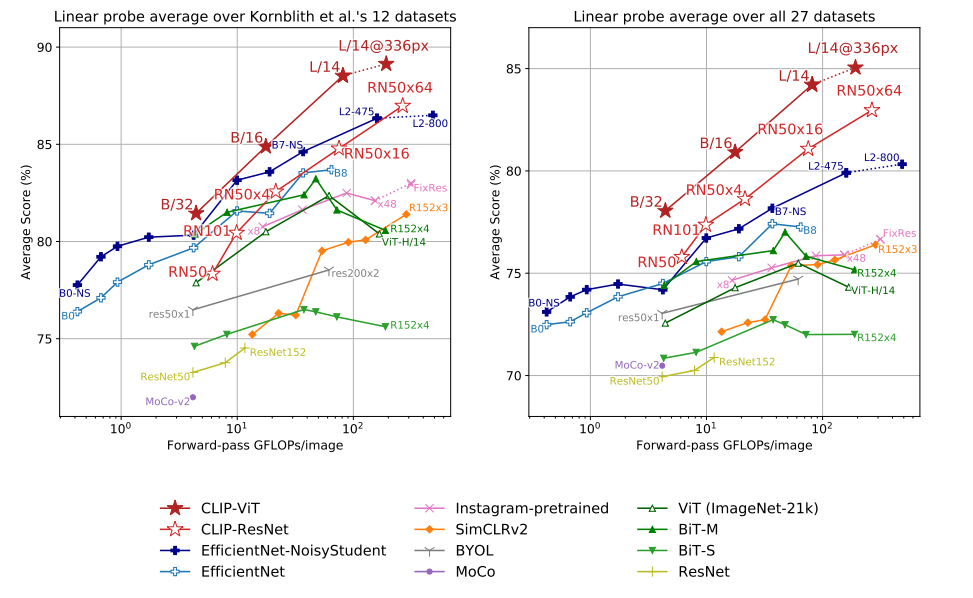
- 作者先在12个数据集上测试了小的clip 然后再扩展到27个数据集上
- 他们的训练方式对于Resnet和ViT两个backbone都是有效的,会比相同backbone在imagenet预训练的效果更好
- ViT相比Resnet不仅能够有更高的计算效率,还能有更好的准确率
- 作者还在地理信息定位,人脸情绪识别等扩展任务上测试了CLIP的效率
3.3 Robustness to Natural Distribution Shift
第一段作者提出了一个问题: 深度学习模型尽管在ImageNet上取得了最好的效果,但是在新的测试集上性能可能会显著下降。 一个可能的解释是: 深度学习模型拟合了数据集和模式的分布情况,但是这些分布在数据集之间的差异是巨大的,因此更换数据集会导致性能的大幅下降。
作者这里找了7个和imagenet不同分布的数据集。 第一个发现是在imagenet上预训练的resnet101只能在imagenet和跟iamgenet构造方法相同的几个数据集上表现相对不错,但是在其他的数据集上会有大量的错误。 这说明这些模型在模型鲁棒性上非常差,并且把这种现象总结为模型对数据集分布的一个虚假的拟合。
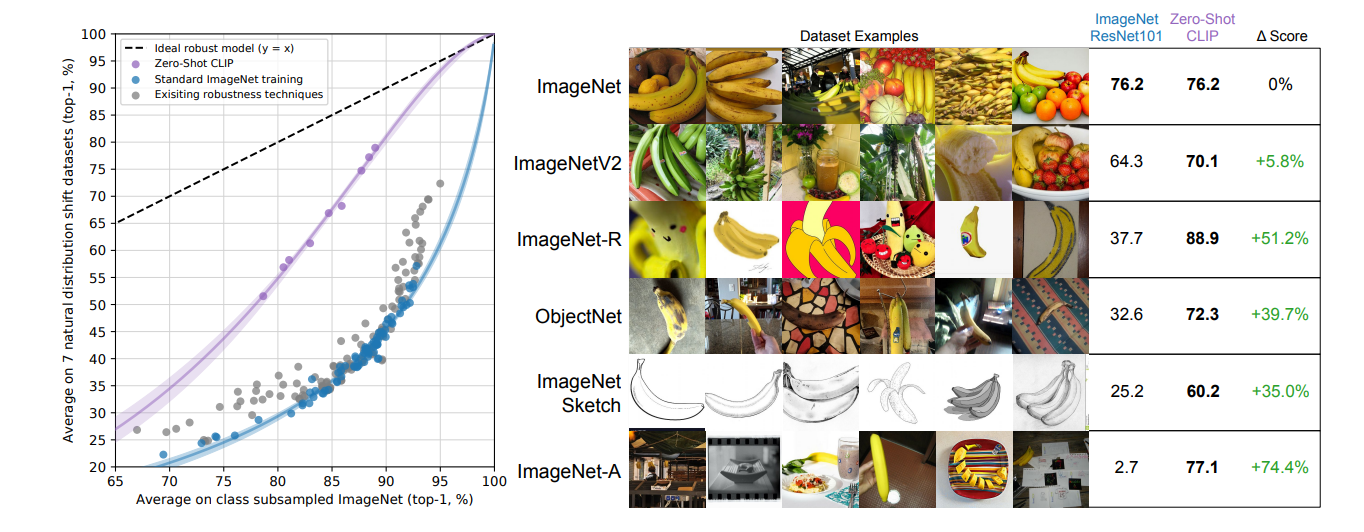
作者认为CLIP对这个问题提供了一个新的研究角度。过去的测试大多是基于在ImageNet上预训练的模型,所以对于和原分布差异很大的样本出现错误是不可避免的。 因为在imagenet上表现良好的模型可能只是拟合得到了一个虚假的数据集的分布。 而zero-shot的模型因为没有在这个数据集上进行训练,所以没有机会去拟合这个特殊的分布。
在imagenet上训练并不一定是导致鲁棒性差的原因。 作者在imagenet上做了全监督的训练,(下图展示)惊讶的发现: CLIP的分类准确率提高了9.2%,这是imagenet上3年的进步的总和,并且达到了2018年SOTA的水平。 但是这个训练导致了在其他数据集上分类准确率的下降。
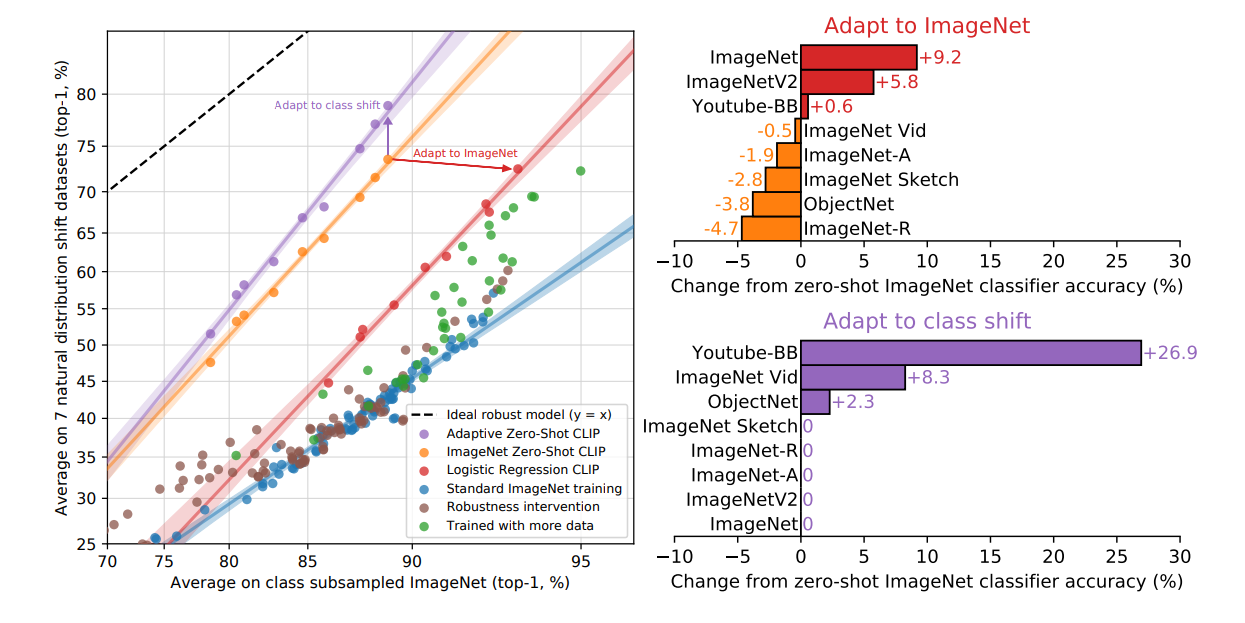
- 理想分布: 模型最鲁邦的情况下,在所有数据集上的预测的准确率都是一样的,无论高低。
最后的实验结果表明:预训练在提高模型的鲁棒性(降低在不同数据集上表现差异)的同时,也导致了在单个数据集上性能的小幅度下降。 这是一个trade-off.
Summary of this section
这一节作者主要从imagenet预训练的模型和CLIP在不同数据集上表现的显著差异出发,针对数据集分布和模型鲁棒性做出了一些分析。 Natural distribution shift 可以理解为不同数据集的不同的分布之间的差异给模型的泛化性带来的挑战。
个人认为CLIP的训练数据足够大量足够多样性,是其鲁棒性(对抗分布偏移)能力强大的原因之一。 另一个原因则是CLIP的训练方法。
前面的章节作者提到了一些通过匹配精准的词汇来进行visual concept classification的工作为什么效果不佳的原因。 即单词和单词组合的空间空间非常大,要从里面找到完全精准的单词是非常困难的事情,并且监督信号会比较稀疏(即两个近义词产生的监督信号可能一个是1一个是0)。 而CLIP用的是embedding+ cosine simlarity的方式,文本信号的特征空间会相对稠密,并且是可训练的,文本的标注也是词组句子而非单个单词。 对比一下分类器的label空间,是one-hot不可训练的,而且相同的class共享同一个标签,在label的空间里,没有恰当对非label出现的词汇的表示。
3.4 Comparison to Human Performance
为了对CLIP做的zeor-shot的任务的难度进行评价,作者构造了一个数据集,让人类在上面做zero-shot测试。 除此之外,还给了人类1-2图片,来观察人类的one-shot和few-shot的能力。
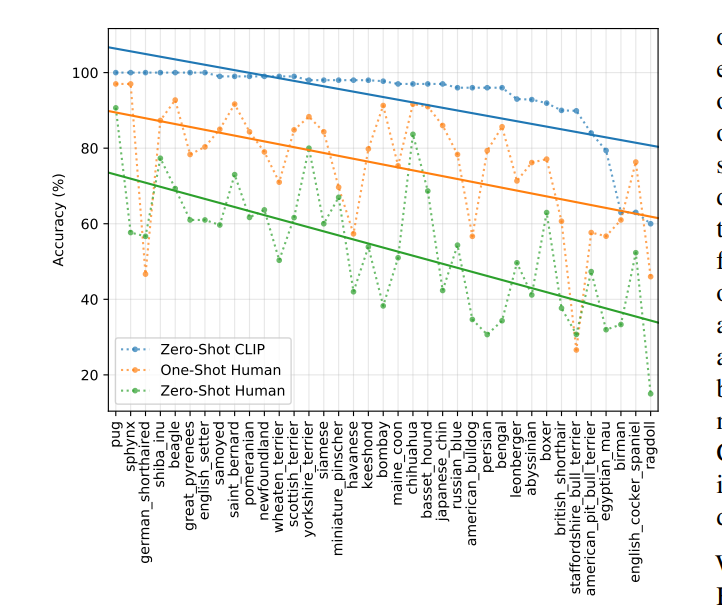
这个图最重要的不是CLIP的能力比人类强,而是人类觉得困难的题目模型也觉得困难,这里体现出来问题的一致性。 这里可以有两个推断的原因:
- 数据集噪音
- out of distribution images
4 Dataset Overlap analysis
在大规模的数据集上进行预训练的时候,难免会测试集信息包含进去。 这会导致下游任务的对泛化能力的测试不稳定。 要去除这种影响,可以预先把测试集从训练数据中剔除。但是这要求预先知道所有的下游任务,这对于CLIP来说是不太现实的。
因此,作者换了一种思路,记录了数据集泄露程度和测试集效果的相关性。(这逆向思维我不得不服)
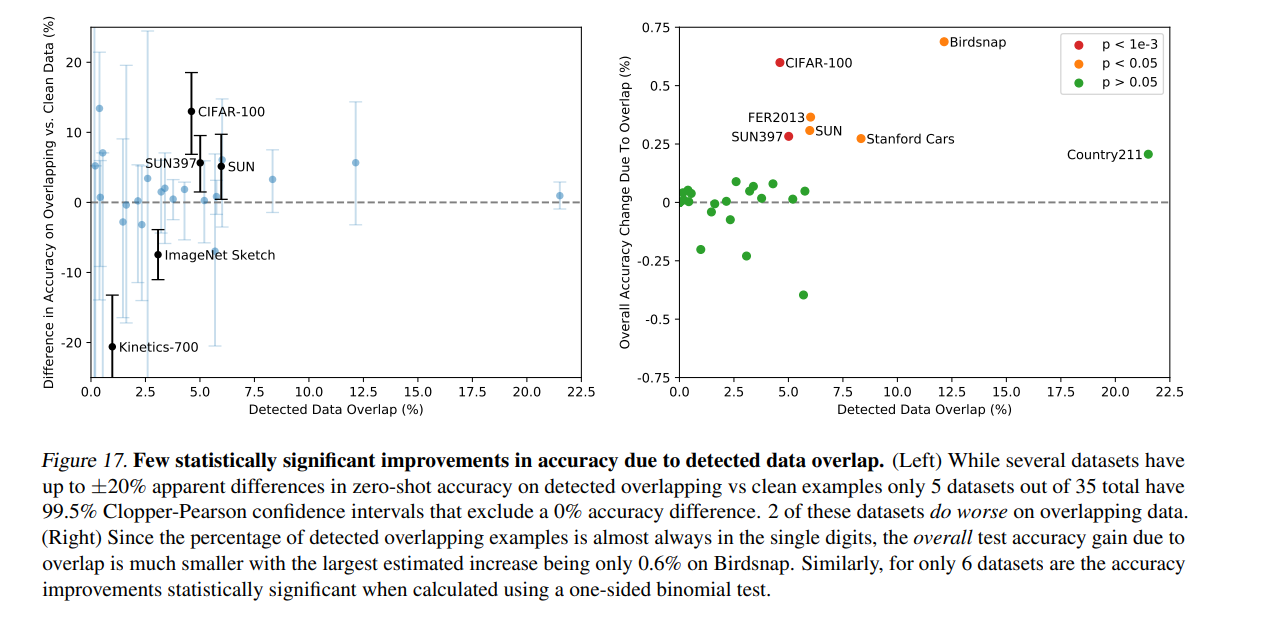
首先通过检索的方法找到一些给定的数据集的测试集出现在训练数据里的概率,然后根据重合率和测试集准确率做统计分析。 发现:1. 有的数据集有泄露但是准确率更低了 2. 只少量数据集表现出了数据集准确率上升和数据泄露之间的统计显著关系。
5 Summary
作者用对比学习的方法将文本特征和图片特征映射到同一个特征空间。
和传统图片分类任务不同的是,传统图片分类将label的特征看作是不可学习的,但是CLIP有一个text_encoder负责学习label特征。 从而将softmax来计算label id 转化成了cosine simlarity.
- section 3.2.3 一张V100也可以训练CLIP模型
6 Comments
- 看CLIP的approch的四节分的叫一个赏心悦目。 一个idea,一个数据集构造,一个训练方法,一个模型。
- 这篇论文有一个很简单的方法,但是有一系列复杂的完善的实验。 这两点都是作者对问题深入的理解的体现。 用一个简单的方法证明了所有的实验。
- Transformer 17 ViT 20 CLIP 21,回过头来看真的一梦黄粱沧海桑田
- 实验和分析方法还是很值得学习和借鉴的,尽管实验有部分是难以复现的
- CLIP写limiation写了一页半 太自信了QAQ
7 Following Work
随着对CLIP的深入探索,很多工作认为CLIP的特征空间并不是想像的那么好。 并不是一个万能的模型。