Diffusion-DPO
Diffusion-DPO阅读笔记,包含LLM-DPO原文的解析
0 Background
0.0 RLHF
人类反馈强化学习
RLHF 是一个复杂且经常不太稳定的过程,它首先拟合一个反应人类偏好的奖励模型,然后通过强化学习对大型无监督 LM 进行微调以最大化评估奖励,并避免与原始模型相差太远

这里

0.1 DPO for LLM
在本文中,我们使用奖励函数和最优策略间的映射,展示了约束奖励最大化问题 完全 可以通过单阶段策略训练进行 优化 ,从本质上解决了人类偏好数据上的分类问题。我们提出的这个算法称为直接偏好优化(_Direct Preference Optimization,DPO)。它具有稳定性、高性能和计算轻量级的特点,不需要拟合奖励模型,不需要在微调时从 LM 中采样,也不需要大量的超参调节。

一个重要的贡献是:跳过显式的奖励建模步骤



(5)->(1)=(6)
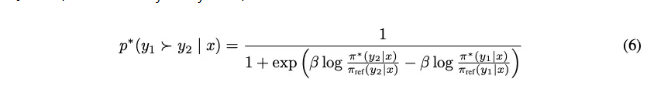
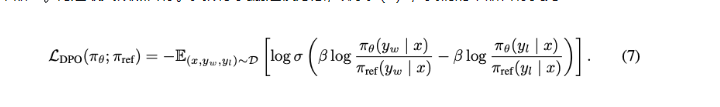

DPO通过重新构造分布改写损失函数让训练的时候不需要跑reward model。把RLHF转换成了SFT。 那么这个过程可以实现,直观上可以这样理解: reward model是从[prompt,win_result , lose_result]这个数据集里面学到分布。 如果用这个数据集在LLM上进行训练,设计一个恰当的损失函数,就可以绕过reward model的采样。
1 Introduction
LLM可以根据人类偏好进行优化,但是在文生图领域很少在训练过程中考虑对人类偏好的优化。
典型的把另一个领域的方法放到本领域。 但是RLHF这个方法为什么可以用在text2image,在什么指标上可能带来提升? 这些都是在开始做之前需要考虑的问题。 RLHF对于任何生成任务都是需要的,因为他们的最终目标都是满足用户需求。
DPO是一种追求更好的模型效率的finetune方法,而Lora这一系列的方法是追求更低的资源消耗。
DPO也可以划分到PEFT的领域。 DPO相对的应该是SFT(supervisied finetuning).
DPO+Lora是可以做的,实践中可以做,但是科研上没有什么novelty.
Text2Image,Text2Video,Image2Video,MM understanding这些都是任务。 我们需要在任务下面找到小的任务进行理解。
看introduction实际上是对taste的一个提升。 这个事情很重要。
Related Work
2.1 Aligning Diffusion Models
Diffusion Models的对齐不只有RLHF这一类方法。 Alignment狭义的也可以理解为让生成模型的分布更加接近于高质量图片的分布。 因此SFT的方法LatentDiffusion和SDXL也都可以算做是alignment。
Emu: samll,curated, high quality dataset benefit visual appeal and text-image alignment.
RL-based methods: DiffusionDDPO和DPOK这类基于强化学习的方法通过最大化奖励函数的方式来学习对齐。 但是他们只能在有限的vocab上训练。
2 Method
2.1 Diffusion Models
2.2 Direct Preference Optimization
2.2.1 奖励函数
用BT模型建模人类偏好,数据集构造为
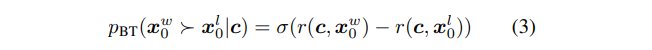
注意到此处BT模型和#0.0 RLHF中的BT模型形式不同,但是带入Sigmoid公式
可以得到
就和之前的式子是相同结构了。
然后用二分类问题利用极大似然训练。
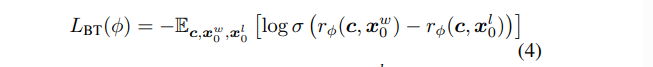
2.2.2 RLHF
RLHF训练过程中一方面最小化
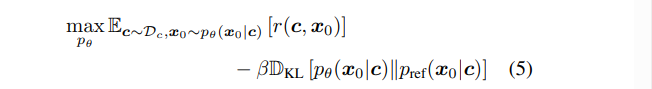
为什么要降低两个分布之间的差异呢?
RLHF期望优化
2.2.3 DPO Objective
DPO Objective In Eq. (5) from [33], the unique global optimal solution
where
Using Eq. (4), the reward objective becomes:
By this reparameterization, instead of optimizing the reward function
这里利用了一些有待研究的参数重整化推导。
2.3 DPO for Diffusion models
这一节关注把DPO从LLM改到Diffusion上面,数据集记为
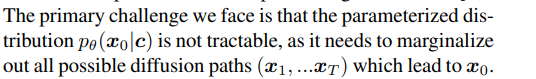
为什么呢
解决这个问题之后,把Loss简化一下,就开始训练。
原始的DPO损失函数:
改到Diffusion上的形式:
先改写成kl散度的形式
再化简为MSE,这个部分Unconditional Diffusion推导过
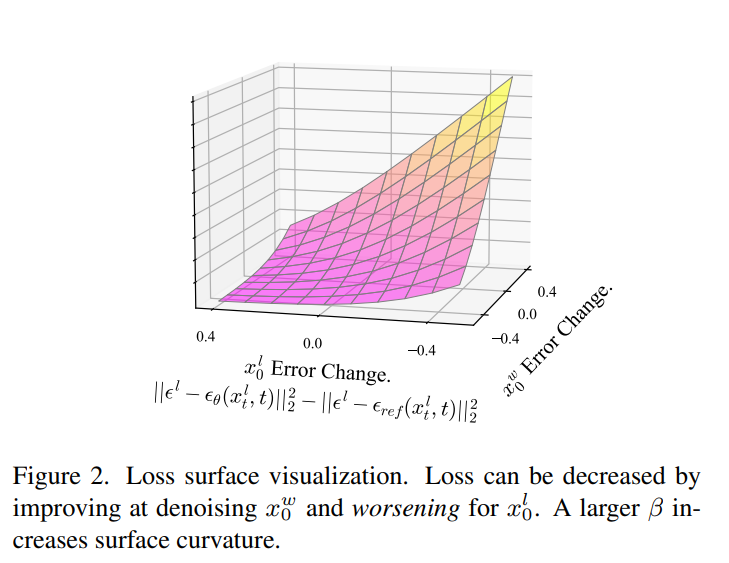
3 Expriments
DDPO:参考模型,但是没有显著提升
| config | value |
|---|---|
| base model | SD.15 SDXL1.0 |
| dataset | Pick-a-Picv2 851,293 pairs, 58,960 unique prompts |
| evaluation | PickScore Hps CLIP |
| GPU | 16 A100 local batch size of 1 128 steps. |
3.1 Primary Results
测试了Diffusion-DPO-SDXL和SDXL-base在(1)General Preference,(2)Visual Appeal和(3)Prompt Alignment下的结果。
最常见的偏好是energetic and dramatic imagery,其次是r quieter/subtler scenes。

DPO-SDXL生成的眼睛更有神,手指更加清楚,这说明模型在处理人脸的时候学习到了更加接近人类偏好的特征。
3.2 image-to-image editing
测试数据集: TEd-Bench
对比方法: SDEdit , noise strength 0.6
给定带颜色的分布图片和文本提示
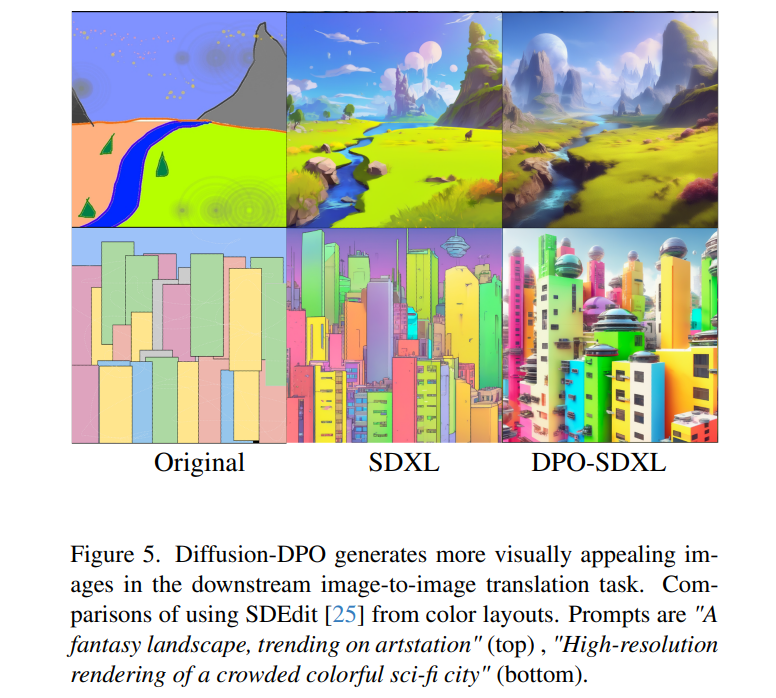
第一行的图片,DPO-SDXL的结果细节更加丰富,包含haze显得更加真实。
第二行的图片,SDXL更像漫画/动画。 DPO-SDXL的结果细节更加丰富,而且风格更加偏向显示。
3.3 Learning from AI feedback
By using a pretrained scoring network for ranking generated images, the model shows improvements in visual appeal and prompt alignment.
将人类标注转化为模型打分,然后根据分数高低来判断正负,然后得到正负样本对。
3.4 实验分析
隐式奖励模型. 隐式的学习奖励函数能够被成功的从LLM改到DIffusion,获得expressivity and generalization的提升。
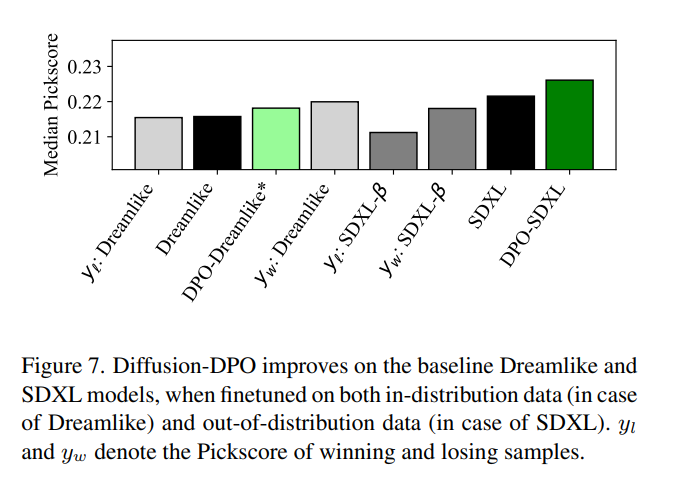
数据显示 DPO在pickscore上可以给Dreamlike,SDXL模型都带来0.01左右的改进。
用SFT在1e-9的学习率和Pick-a-Pic数据集下训练SD1.5收敛并有改进。 但是在SDXL上会让模型表现变差。 原因可能是Pick-a-Pic数据集质量高于SD1.5
4 Dataset Construction
yuvalkirstain/pickapic_v2 · Datasets at Hugging Face
5 Summary & Comments
LLM上的DPO的主要贡献是:通过将省略了奖励模型r的训练,将强化学习过程转化为训练一个条件生成模型。 DPO损失函数的梯度要求提高生成win样本概率,降低生成lose样本的概率。
本文的工作将原来LLM的DPO损失函数改写到Diffusion上,然后利用Diffusion的一些性质将损失化简成几个噪声预测。 通过SDXL SD1.5的实验证明DPO在Diffusion中的有效性。
一些想法:
- 两个工作相似的地方是: 都是通过推导损失函数来绕开了DIffusion训练过程的额外的预训练模型。
- 作者提到personal preference可能会有探索价值
现在的问题是:
- 我对RL的方法不太熟悉,我不太确定是否需要深入了解。
作者提到的未来方向:
The area of personal or group preference tuning is an exciting area of future work.
6 Implementation Analysis
DiffusionDPO的训练是基于diffusers的训练代码。
提供了DPO和SFT两种训练策略。
预处理函数preprocess_train负责把图片连接成一整个batch
choice model是ranking model [hps,aes,clip] ,应该对应AI feedback
训练循环从trian.py 1002行开始
base model please refer to SD1.5 & SDXL
6.1 Loss Implementation
torch.chunk: 这个方法将张量 沿着dim=1分成两块。假设 channels 的数量为 C,那么这个操作将把 C 个通道分成两组,每组约为 C/2 个通道。
# model_pred and ref_pred will be (2 * LBS) x 4 x latent_spatial_dim x latent_spatial_dim
# losses are both 2 * LBS
# 1st half of tensors is preferred (y_w), second half is unpreferred
model_losses = (model_pred - target).pow(2).mean(dim=[1,2,3])
model_losses_w, model_losses_l = model_losses.chunk(2)
# below for logging purposes
raw_model_loss = 0.5 * (model_losses_w.mean() + model_losses_l.mean())
model_diff = model_losses_w - model_losses_l # These are both LBS (as is t)
with torch.no_grad(): # Get the reference policy (unet) prediction
ref_pred = ref_unet(*model_batch_args,added_cond_kwargs = added_cond_kwargs).sample.detach()
ref_losses = (ref_pred - target).pow(2).mean(dim=[1,2,3])
ref_losses_w, ref_losses_l = ref_losses.chunk(2)\
ref_diff = ref_losses_w - ref_losses_l
raw_ref_loss = ref_losses.mean()
scale_term = -0.5 * args.beta_dpo
inside_term = scale_term * (model_diff - ref_diff)
implicit_acc = (inside_term > 0).sum().float() / inside_term.size(0)
loss = -1 * F.logsigmoid(inside_term).mean()
ref_unet是一个预训练的unet
6.2 Dataset Construction
从数据集上来看,win和loss的Image在Dataset类里面是同样的地位,只是紧挨在一起的,并且共享同一个caption.
用Huggingface数据集load_dataset方法来加载pickapic数据,也就是一个imagefolder类型的数据集。
DATASET_NAME_MAPPING = {
"yuvalkirstain/pickapic_v1": ("jpg_0", "jpg_1", "label_0", "caption"),
"yuvalkirstain/pickapic_v2": ("jpg_0", "jpg_1", "label_0", "caption"),
}
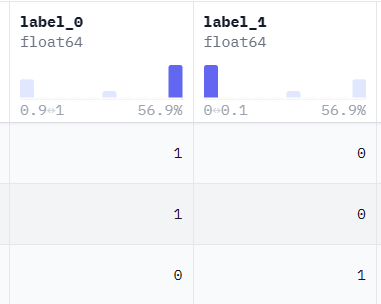
6.2.1 label
label是[0,0.5,1]分别表示lose,equal,win
6.2.2 preprocess and collate_fn
数据集先用preprocess_train处理,再在Loader阶段用collate_fn聚合
preprocess_train将图片在channel dim上堆叠,先是label=1的样本再是label=0的样本 [B,2C,H,W]
collate_fn将Pixel_value和tokenized value进行堆叠。
这里在Channel dim上堆叠为了方便之后再torch.chunk分离两个样本,同时也保证了前面的是win后面的是lose。
LVDM的MacVid取出来是[C,L,H,W],在batch之后Channel dim仍然在第二维。所以chunk的部分代码不变。
7 Relative Following Papers
- DDPO
- Dreamlike
- HPS
8 Relative Blogs
Paper Review
[Paper Review:Diffusio DPO](https://andlukyane.com/blog/paper-review-diffusion-dpo
Al learning feedback:
By using a pretrained scoring network for ranking generated images, the model shows improvements in visual appeal and prompt alignment.
https://zhuanlan.zhihu.com/p/694392956?utm_psn=1766790705710661632
一个关于DPO如何简化RLHF的简单转述