SAPO 无需构造数据的对齐
1 Introduction
1.1 Problem Statement
DPO训练的时候要求构造配对的数据,这不好构造
此处省略去我构造配对数据时候的心酸泪目
所以作者希望探索出一种替代方案,降低构造数据的成本,提高RLHF的效果。
1.2 Stated Contribution
- 自增强的方法
- scalable training paradigm
2 Related Work
2.1 RLHF
RLHF: Reinforcement Learning from Human Feedback
强化学习概念:
- Offline learning 离线学习: 预先收集好数据集 不需要新的reward和新的标
- On-Policy Learning 适用于希望通过当前策略生成的数据进行实时优化的场景,但可能会面临数据效率低和探索不足的问题。
- Off-Policy Learning 则允许利用不同策略生成的数据进行学习,提供了更高的数据利用效率和更广泛的学习体验,但也增加了实现的复杂性和稳定性挑战。
相关文献: - PPO(Proximal Policy Optimization): 训练好一个reward model 给带训练的模型进行反馈
- DPO(Direct Preference Optimization): 无需训练reward model ,直接微调
- Slic-HF: contrastive ranking calibration loss来改进打分效果
- RPO(Relative Preference Optimization):用contrastive weighting 来评价相关的prompt之间的语义相似度,支持非配对的数据和配对数据训练
- ORPO: SFT+PO 的方式同样也不需要ref_model
ORPO (Odds Ratio Preference Optimization):
- Objective: Provide a method for optimizing policy models without needing a reference model.
- Approach: Employs log odds ratios to directly contrast favored and disfavored responses during SFT, simplifying model alignment.
Formulas:
- DPO Loss Function:
- ORPO Odds Definition:
- ORPO Loss Function:
3 Method
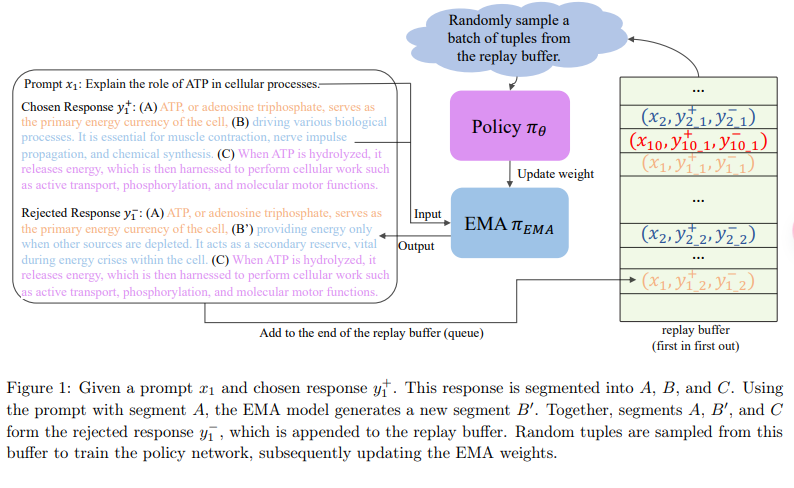
首先对于一个输入x和一个选定的正样本y,将y分割成3段,然后让模型生成中间段,作为负样本y'。 然后这个正负样本对被加入了一个队列。 训练过程中,随机从这个队列里面采样tuple,然后作为训练policy network的输入。 最后滑动平均地更新这个
这个和moco的memory bank真的越来越像了,逐渐更新的队列。

4 Experiment
4.1 Implementation Details
Training Details Summary
Hardware:
- Training conducted on 8 Nvidia H100 GPUs.
Training Hyperparameters:
- Detailed hyperparameters for baseline experiments can be found in Appendix A.
- Followed foundational settings consistent with DPO (Direct Preference Optimization) [Rafailov et al., 2023] and ORPO (Odds Ratio Preference Optimization) [Hong et al., 2024].
SAPO Method Specifics:
- Maximum prompt length: 1792 tokens.
- Maximum total length for prompts and responses: 2048 tokens.
- Training duration: 4 epochs.
- Segment length for teacher-forcing supervision: 256 tokens.
- Replay buffer size: 2000.
- For each prompt and chosen response, one corresponding rejected response was sampled.
- Update coefficient (\alpha) for the EMA (Exponential Moving Average) model: 0.5.
- EMA model updated every two training steps.
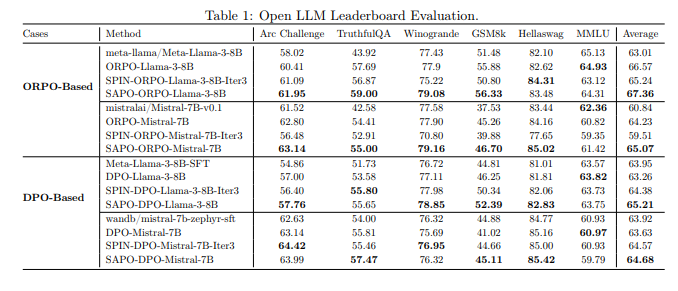
4.2 Evaluation
5 Summary
5.1 Relative Position
- 没有修改损失函数,可以和DPO,ORPO等不同的损失函数公用
- 这是一个数据构造方法+训练pipeline
6 Comments
提供了一种构造负样本的思路,并且证明了有效性。 有放到视觉生成模型上的潜力。
CV里面这样的agument 很多, 按照inpainting的思路,mask一部分生成作为negative也可以做。
7 Supp.
7.1 SLiC-HF: Sequence Likelihood Calibration with Human Feedback
这篇论文介绍了一种名为SLiC-HF的新方法,它通过人类反馈来校准语言模型的序列概率,提供了一种比传统RLHF更简单、更高效的替代方案。研究显示,SLiC-HF在Reddit TL;DR摘要任务上显著提升了性能,并且能够利用为其他模型收集的反馈数据,减少了新数据收集的成本。此外,论文还提供了一个基于开源T5模型的SLiC-HF实现,该实现在自动和人类评估中均优于RLHF方法。