SimPO 无需ref_model的LLM对齐
One-line summary
通过修改奖励函数,去除掉DPO训练中需要的ref_model
1 Introduction
1.1 Problem Statement
DPO是一种离线的偏好学习优化算法,通过重参数化强化学习中的奖励函数来学习人类偏好,同时加强训练的稳定性和简单性。 SimPO是一种更加简单有效的方法:用一个序列的平均对数概率作为隐式的奖励。
- 更好的和模型生成过程对齐,不需要reference model
- 计算更加简单,内存消耗更少
1.2 Stated Contribution
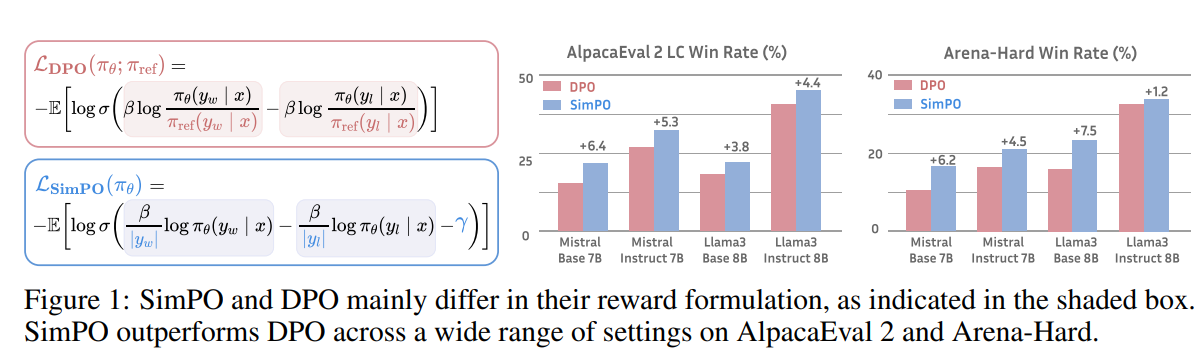
DPO的公式
SIMPO公式
注意,SimPO不需要一个reference model,这意味着这个训练的时候需要的显存的数量可以大大减少了。
2 DPO preliminaries
r是一个奖励函数,一个带有闭式解的表达式作为优化策略:
然后用Bradly-Terry排序目标
得到DPO的优化目标:最小化负对数的BT:
3 SimPO: Simple Preference Optimization
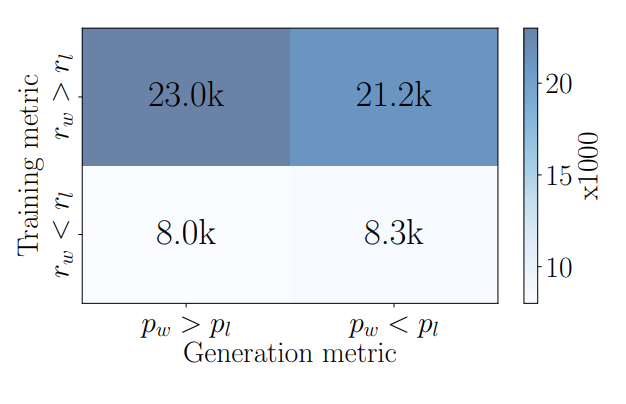
3.1 DPO奖励和LM生成目标之间的差异
语言模型生成一个序列的时候是通过最大化平均对数似然(maximizes the average log likelihood):
这个目标和奖励函数r有不一致的地方,也就是说
如下图所示,直观的可以看书r大的不一定概率大
3.2 长度归一化的奖励函数
为了解决这个问题,SimPO改了奖励函数
从:
到
这个平均最小的奖励函数和LM生成的时候的式子类似,然后就可以解决3.1里提到的问题
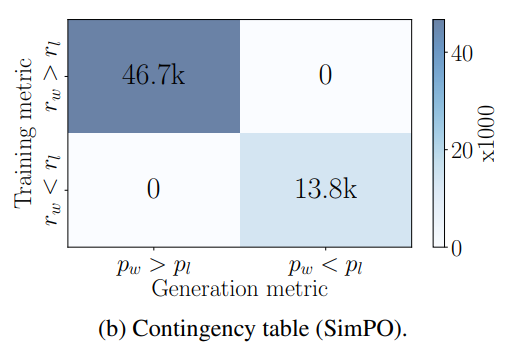
3.3 最小奖励差距
方法部分结束
4 Experiment
4.1 Implementation Details

5 Summary
从语言模型的生成过程的目标推导出了减小generation和reward之间差异的新的reward function
去掉了对ref_model的依赖
加入了一个最小的奖励差距
得到一个简单的preference optimization loss
6 Comments
有几个问题:
- alignment对于llm的重要性要高于其对于其他模态的大模型吗?
- 3.1的分析很有insight.